
I’m slowly immersing myself in the singing synthesis technology behind the Casio CT-S1000V. Heck, ya need somethin’ to do during TV advertisements while watching sports. 🙂
There are two major approaches to speech (singing) synthesis: unit-selection and statistical parametric.
Most people are familiar with unit-selection systems like Texas Instruments old Speak and Spell or the much more advanced Yamaha Vocaloid™. Unit-selection relies upon a large database of short waveform units (AKA phonemes) which are concatenated during synthesis. The real trick behind natural sounding singing (and speech) is the connective “tissue” between units. Vocaloid creates waveform data that connects individual phonetic units.
If you are familiar with Yamaha’s Articulation Element Modeling (AEM), a light should have lit in your mind. The two technologies have similarities, i.e., joining note heads, bodies, and tails. The Yamaha NSX-1 chip implements a stripped down Vocaloid engine and Real Acoustic Sound (AEM).
The content and size of the unit waveform database is a significant practical problem. The developers must record, organize and store a huge number of sampled phrases (waveform units). The Vocaloid 2 Tonio database (male, operatic English singer) occupies 750MBytes on my hard drive — not small and was a real challenge to collect, no doubt.
Statistical parametric systems effectively encode the source phonetic sounds into a model such as an hidden Markov model (HMM). During training, the source speech is subdivided into temporal frames and the individual frames are reduced to acoustic parameters. The model learns to associate specific text with the corresponding acoustic parameters. During synthesis, the model is fed text and acoustic parameters are recalled by the model. The acoustic parameters drive some form of vocoding. (“Vocoding” is used broadly here.)
Deep neural networks (DNN) improve on HMM. Sinsy is a DNN-based singing voice synthesis (SVS) system from Nogoya Institute of Technology. It is the culmination of many years of research by sensei Professor Keiichi Tokuda, his students and colleagues. It was partially supported by the Casio Science Promotion Foundation. Thus, adoption by Casio is hardly accidental!
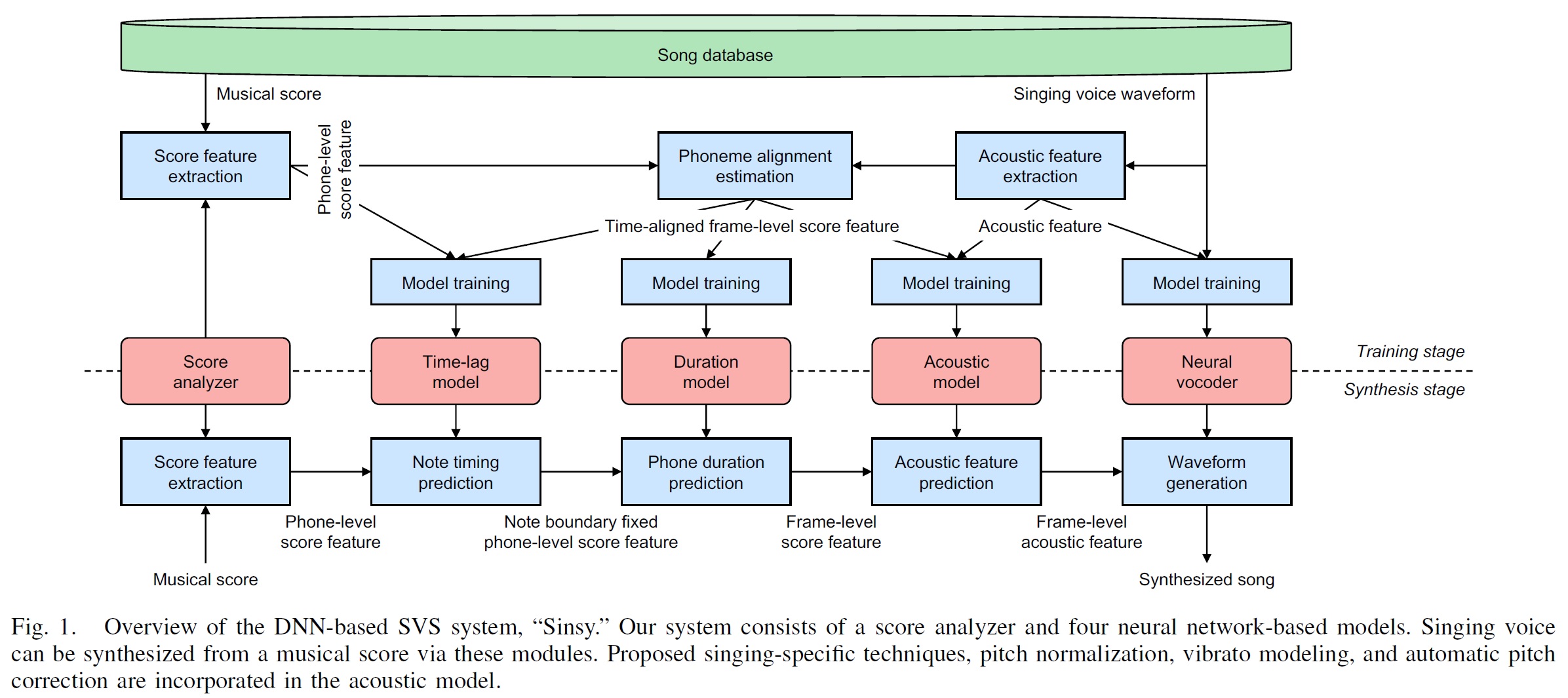
The Sinsy block diagram is taken from their paper: Sinsy: A Deep Neural Network-Based Singing Voice Synthesis System, by Yukiya Hono, Kei Hashimoto, Keiichiro Oura, Yoshihiko Nankaku, and Keiichi Tokuda, EEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 2803-2815, 2021. The method is quite complex and consists of several models. It’s not clear (to me, yet) if the Casio approach has all elements of the Sinsy approach. I recommend reading the paper, BTW; it’s well-written and highly technical.
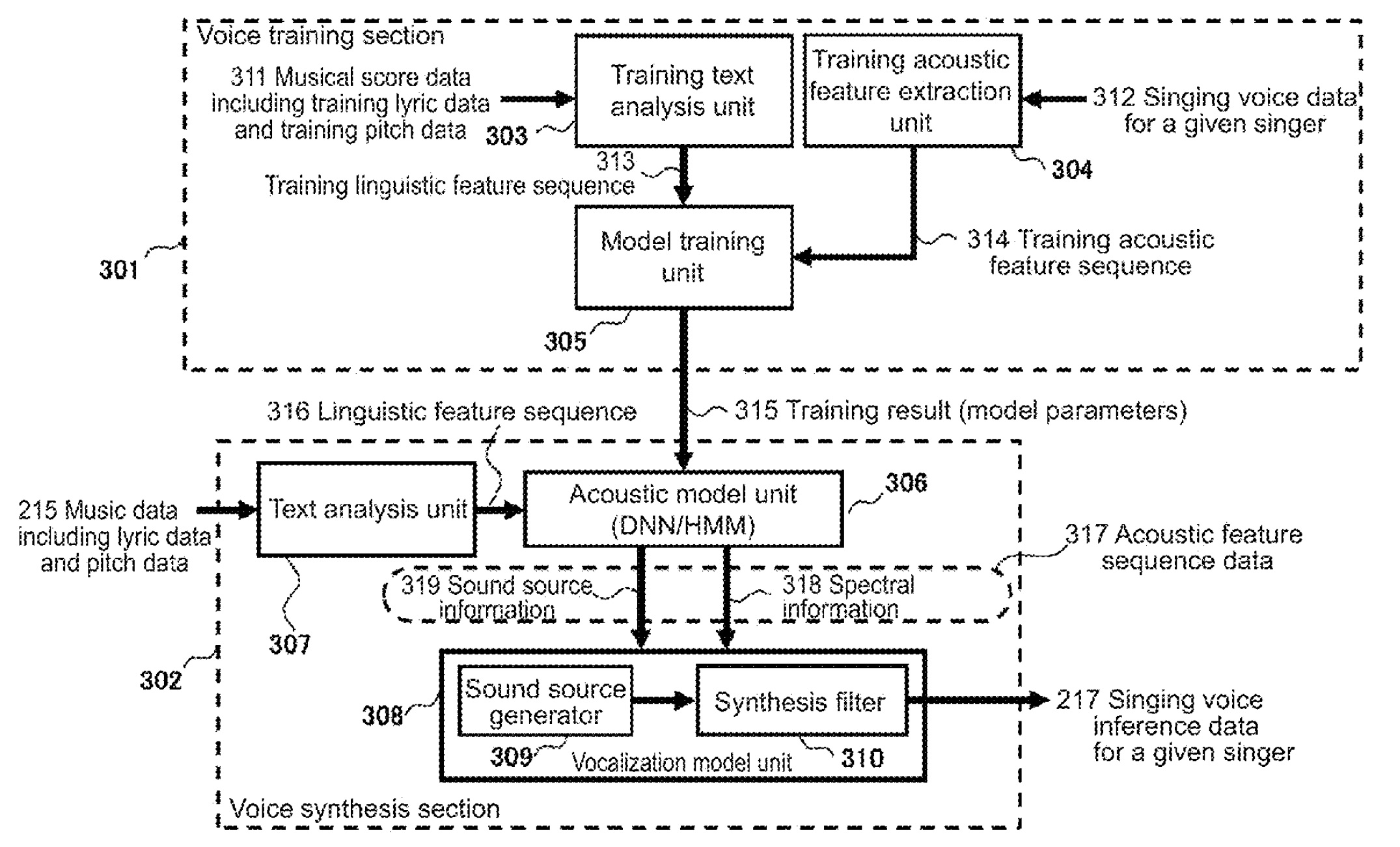
The next block diagram is taken from Casio’s U.S. Patent number 10,789,922 awarded September 29, 2020. Their approach is separated into a training phase and a synthesis (playing) phase. You’ll notice that Casio employ only an acoustic model. The patent discloses a “Voice synthesis LSI” unit, so their software may have a hardware assist. We’ll need to take a screwdriver to the CT-S1000V to find out for sure!
A picture is worth a thousand words. A technical diagram, however, requires a little interpretive context. 😉 Paraphrasing the Casio patent:
The text analysis unit produces phonemes, parts of speech, words and pitches. This information is sent to the acoustic model. The acoustic model unit estimates and outputs an acoustic feature sequence. The acoustic model represents a correspondence between the input linguistic feature sequence and the output acoustic feature sequence. Acoustic feature sequence includes:
- Spectral information modeling the vocal tract (cepstrum MEL coefficients, line spectral pairs, or similar).
- Sound source information modeling vocal chords (fundamental pitch frequency (F0) and power value).
The vocalization model unit receives the acoustic feature sequence. It generates singing voice inference data for a given singer. The singing voice inference data is output through a digital-to-analog converter (DAC). The vocalization model unit consists of:
- A sound source generator:
- Generates a pulse train for voiced phonemes.
- Generates white noise for unvoiced phonemes.
- A synthesis filter:
- Uses the output signal from the sound source generator.
- Is a digital filter that models the vocal tract based on spectral information.
- Generates singing voice inference data (AKA “samples”).
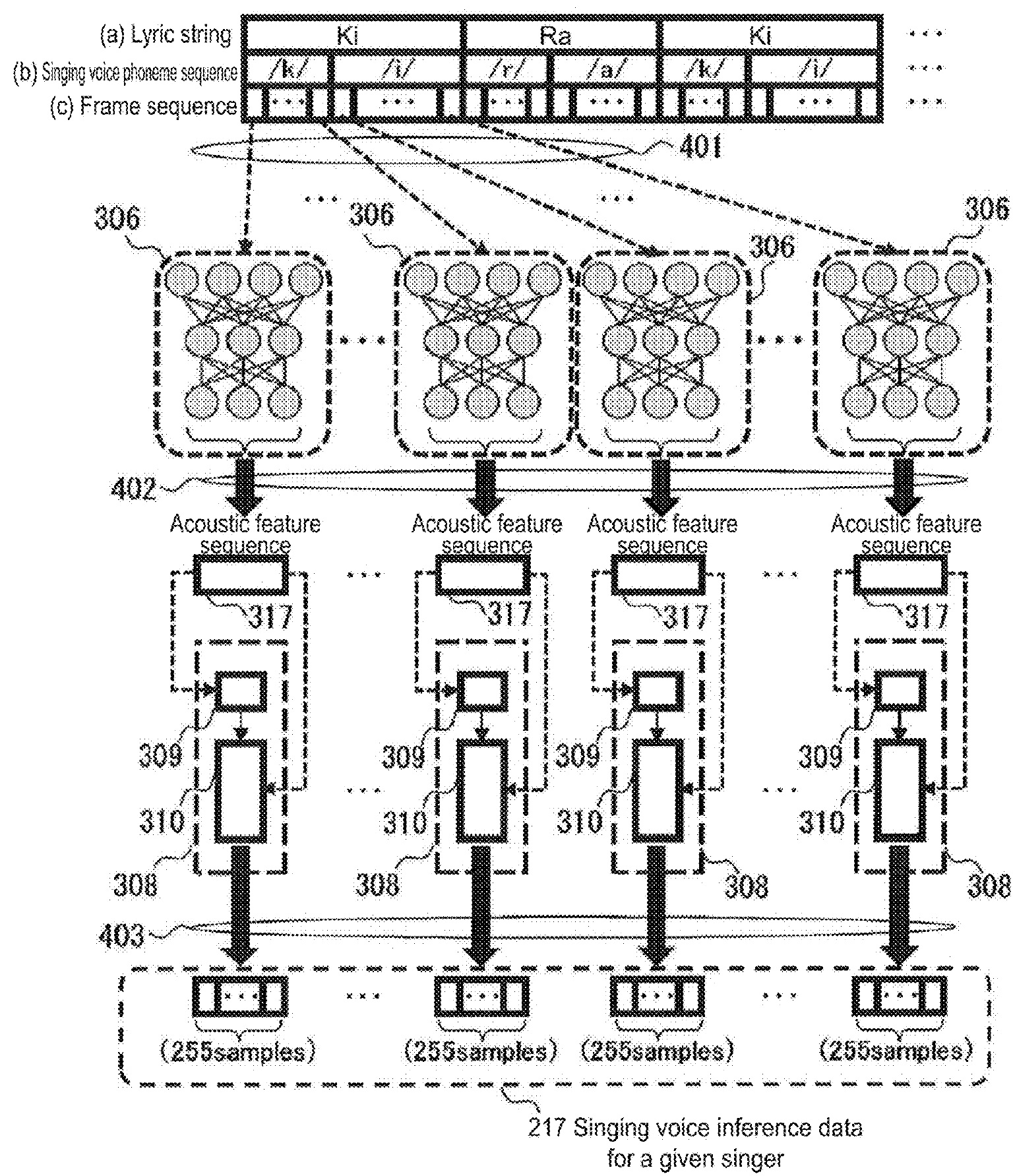
This rather complicated diagram from U.S. Patent 10,789,922 shows the synthesis phase in more detail. It shows the lyric string decomposed into phoneme and frame sequences. Each frame is sent to an acoustic model which generates an acoustic feature sequence, that is, the acoustic parameters that were learned during training. The acoustic parameters are synthesized (vocoded) into 255 samples. Each frame is about 5.1 msec long.
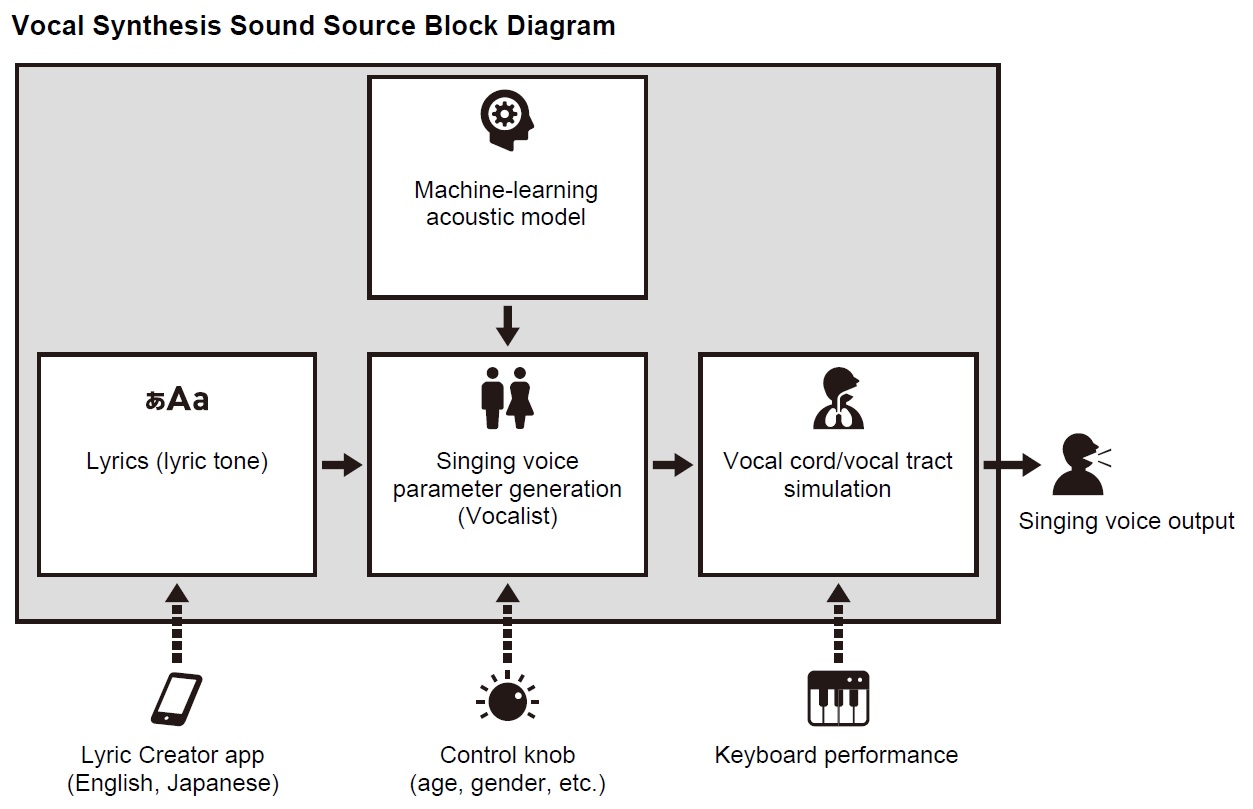
Well, if the second patent diagram was TMI, here is the block diagram from the Casio CT-S1000V user guide. The simplified diagram is quite concise and accurate! You should be able to relate these blocks directly back to the patent.
I hope this discussion is informative. In a later post, I’ll take a look at a few practical details related to Casio CT1000V Vocal Synthesis.
Copyright © 2022 Paul J. Drongowski