
As mentioned in my earlier post, the Yamaha NSX-1 integrated circuit implements three sound sources: a General MIDI engine based on the XG voice architecture, eVocaloid and Real Acoustic Sound (RAS). RAS is based on Articulation Element Modeling (AEM) and I now believe that eVocaloid is also a form of AEM. eVocaloid uses AEM to join or “blend” phonemes. The more well-known “conventional” Vocaloid uses computationally intensive mathematics for blending which is why conventional Vocaloid remains a computer-only application.
Vocaloid uses a method called Frequency-domain Singing Articulation Splicing and Shaping. It performs frequency domain smoothing. (That’s the short story.)
AEM underlies Tyros Super Articulation 2 (S.Art2) voices. Players really dig S.Art2 voices because they are so intuitively expressive and authentic. Synthesizer folk hoped that Montage would implement S.Art2 voices — a hope not yet realized.
Conceptually, S.Art2 has two major subsystems: a controller and a synthesis engine. The controller (which is really software running on an embedded microcomputer) senses the playing gesture made by the musician and translates those gestures into synthesis actions. Gestures include striking a key, releasing a key, pressing an articulation button, moving the pitch bend or modulation wheel. Vibrato is the most commonly applied modulation type. The controller takes all of this input and figures out the musician’s intent. The controller then translates that intent into commands which it sends to the synthesis engine.
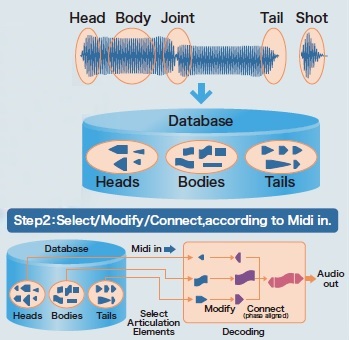
AEM breaks synthesis into five phases: head, body, joint, tail and shot. The head phase is what we usually call “attack.” The body phase forms the main part of a tone. The tail phase is what we usually call “release.” The joint phase connects two bodies, replacing the head phase leading into the second body. A shot is short waveform like a detached staccato note or a percussive hit. A flowing legato string passage sounds much different than pizzicato, so it makes sense to treat shots separately.
Heads, bodies and tails are stored in a database of waveform fragments (i.e., samples). Based on gestures — or MIDI data in the case of the NSX-1 — the controller selects fragments from the database. It then modifies and joins the fragments according to the intent to produce the final digital audio waveform. For example, the synthesis engine computes joint fragments to blend two legato notes. The synthesis engine may also apply vibrato across the entire waveform (including the computed joint) if requested.
Whew! Now let’s apply these concepts to the human voice. eVocaloid is driven by a stream of phonemes. The phonemes are represented as an ASCII string of phonetic symbols. The eVocaloid controller recognizes each phoneme and breaks it down into head, body and tail fragments. It figures out when to play these fragments and when bodies must be joined. The eVocaloid controller issues internal commands to the synthesis engine to make the vocal intent happen. As in the case of musical passages, vibrato and pitch bend may be requested and are applied. The NSX-1 MIDI implementation has three Non-Registered Parameter Number (NRPN) messages to control vibrato characteristics:
- Vibrato Type
- Vibrato Rate
- Vibrato Delay
I suspect that a phoneme like “ka” must be two fragments: an attack fragment “k” and a body fragment “a”. If “ka” is followed immediately by another phoneme, then the controller requests a joint. Otherwise, “ka” is regarded as the end of a detached word (or phrase) and the appropriate tail fragment is synthesized.
Whether it’s music or voice, timing is critical. MIDI note on and note off events cue the controller as to when to begin synthesis and when to end synthesis. The relationship between two notes is also critical as two overlapping notes indicate legato intent and articulation. The Yamaha AEM patents devote a lot of space to timing and to mitigation of latency effects. The NSX-1 MIDI implementation has two NRPN messages to control timing:
- Portamento Timing
- Phoneme Unit Connect Type
The Phoneme Unit Connect Type has three settings: fixed 50 msec mode, minimum mode and velocity mode in which the velocity value changes the phoneme’s duration.
As I mentioned earlier, eVocaloid operates on a stream of phonetic symbols. Software sends phonetic symbols to the NSX-1 using either of two methods:
- System Exclusive (SysEx) messages
- NRPN messages
A complete string of phonetic symbols can be sent in a single SysEx message. Up to 128 phonetic symbols may be sent in the message. The size of the internal buffer for symbols is not stated, but I suspect that it’s 128 symbols. The phoneme delimiter is ASCII space and the syllable delimiter is ASCII comma. A NULL character must appear at the end of the list.
The NRPN method uses three NRPN message types:
- Start of Phonetic Symbols
- Phonetic Symbol
- End of Phonetic Symbols
In order to send a string of phonetic symbols, software sends a start NRPN message, one or more phonetic symbol NRPN messages and, finally, an end of phonetic symbols NRPN message.
Phonetic symbols are stored in a (128 byte?) buffer. The buffer lets software send a phrase before it is played (sung) by the NSX-1. Each MIDI note ON message advances a pointer through the buffer selecting the next phoneme to be sung. The SEEK NRPN message lets software jump around inside the buffer. If software wants to start at the beginning of the buffer, it sends a “SEEK 0” NRPN message. This capability is really handy, potentially letting a musician start at the beginning of a phrase again if they have lost their place in the lyrics.
When I translated the Yamaha NSX-1 brochure, I encountered the statement: “eVocaloid and Real Acoustic Sound cannot be used at the same time. You need to choose which one to pre-install at the ordering stage.”. This recommendation is not surprising. Both RAS and eVocaloid must have its own unique database; RAS has instrument samples and eVocaloid has human vocal samples. I don’t think, therefore, that Pocket Miku has any RAS (AEM) musical instrument samples. (Bummer.)
Speaking of databases, conventional Vocaloid databases are quite large: hundreds of megabytes. eVocaloid is intended for embedded applications and eVocaloid databases are much smaller. I’ll find out how big once I take apart Pocket Miku. Sorry, Miku. 🙂
I hope this article has given you more insight into Yamaha Real Acoustic Sound and eVocaloid.
Copyright © 2017 Paul J. Drongowski