So far, I’ve posted several articles with resources for the Yamaha NSX-1 eVocaloid integrated circuit and the Gakken Pocket Miku (NSX-39), which is based on the NSX-1 chip. (See the bottom of this page for links.) This post pulls the pieces together.
Pocket Miku is both a vocal stylophone and a Yamaha XG architecture General MIDI (GM) module. There are plenty of Pocket Miku stylophone demos on the Web, so I will concentrate on Pocket Miku as a module.

Pocket Miku connects to your PC, mobile device or whatever over USB. The module implements sixteen MIDI channels where channel one is always assigned to the Miku eVocaloid voice and channels 2 to 16 are regular MIDI voices. As I said, the module follows the XG architecture and you can play with virtually all of the common XG features. The NSX-1 within Pocket Miku includes a fairly decent DSP effects processor in addition to chorus and reverb. The DSP effect algorithms include chorus, reverb, distortion, modulation effects, rotary speaker and a lot more. Thus, Pocket Miku is much more than a garden variety General MIDI module.
My test set up is simple: Pocket Miku, a USB cable, a Windows 7 PC, Cakewalk SONAR and a MIDI controller. Pocket Miku’s audio out goes to a pair of Mackie MR5 Mk3 monitors. The MP3 files included with this post were recorded direct using a Roland MicroBR recorder with no added external effects.
The first demo track is a bit of a spontaneous experiment. “What happens if I take a standard XG MIDI file and sling it at Pocket Miku?” The test MIDI file is “Smooth Operator” from Yamaha Musicsoft. Channel 1 is the vocal melody, so we’re off to a fast start right out of the gate.
One needs to put Pocket Miku into NSX-1 compatibility mode. Simultaneously pressing the U + VOLUME UP + VOLUME DOWN buttons changes Pocket Miku to NSX-1 compatibility mode. (Pocket Miku responds with a high hat sound.) Compatibility mode turns off the NSX-39 SysEx implementation and passes everything to the NSX-1 without interpetation or interference. This gets the best results when using Pocket Miku as a MIDI module.
Here is the MP3 Smooth Operator demo. I made only one change to the MIDI file. Unmodified, Miku’s voice is high enough to shatter glass. Yikes! I transposed MIDI channel 1 down one octave. Much better. Pocket Miku is singing whatever the default (Japanese) lyrics are at start-up. It’s possible to send lyrics to Pocket Miku using SysEx messages embedded in the MIDI file. Too much effort for a spontaneous experiment, so what you hear is what you get.
Depending upon your expectations about General MIDI sound sets, you’ll either groan or think “not bad for $40 USD.” Miku does not challenge Sade.
One overall problem with Pocket Miku is its rather noisy audio signal. I don’t think you can fault the NSX-1 chip or the digital-to-analog converter (DAC). (The DAC, by the way, is embedded in the ARM architecture system on a chip (SOC) that controls the NSX-1.) The engineers who laid out the NSX-39 circuit board put the USB port right next to the audio jack. Bad idea! This is an example where board layout can absolutely murder audio quality. Bottom line: Pocket Miku puts out quite a hiss.
The second demo is a little more elaborate. As a starting point, I used a simple downtempo track assembled from Equinox Sounds Total Midi clips. The backing track consists of electric piano, acoustic bass, lead synth and drums — all General MIDI. Since GM doesn’t offer voice variations, there’s not a lot of flexibility here.
I created an (almost) tempo-sync’ed tremolo for the electric piano by drawing expression controller events (CC#11). My hope was to exploit the DSP unit for some kind of interesting vocal effect. However, everything I tried on the vocal was over-the-top or inappropriate. (Yes, you can apply pitch change via DSP to get vocal harmony.) Thus, Miku’s voice is heard unadulterated. I eventually wound up wasting the DSP on a few minor — and crummy — rhythm track effects.
I created four lyrical phrases:
A summer day Natsu no hi
f0 43 79 09 00 50 10 6e 20 61 2c 74 73 20 4d 2c 6e 20 6f 2c 43 20 69 00 f7
Your face Anata no kao
f0 43 79 09 00 50 10 61 2c 6e 20 61 2c 74 20 61 2c 6e 20 6f 2c 6b 20 61 2c 6f 00 f7
A beautiful smile Utsukushi egao
f0 43 79 09 00 50 10 4d 2c 74 73 20 4d 2c 6b 20 4d 2c 53 20 69 2c 65 2c 67 20 61 2c 6f 00 f7
A song for you Anata no tame no uta
f0 43 79 09 00 50 10 61 2c 6e 20 61 2c 74 20 61 2c 6e 20 6f 2c 74 20 61 2c 6d 20 65 2c 6e 20 6f 2c 4d 2c 74 20 61 00 f7
The Japanese lyrics were generated by Google Translate. I hope Miku isn’t singing anything profane or obscene. 🙂
I did not create the SysEx messages by hand! I used the Aides Technology translation app. Aides Technology is the developer of the Switch Science NSX-1 Arduino shield. The application converts a katakana phrase to an NSX-1 System Exclusive (SysEx) message. Once converted, I copied each HEX SysEx message from the Aides Tech page and pasted them into SONAR.
Finally, the fun part! I improvised the Miku vocal, playing the part on a Korg Triton Taktile controller. What you hear in the MP3 Pocket Miku demo is one complete take. The first vocal section is without vibrato and the second vocal section is with vibrato added to long, held notes. I added vibrato manually by drawing modulation (CC#1) events in SONAR, but I could have ridden the modulation wheel while improving instead.
The overall process is more intuitive than the full Vocaloid editor where essentially everything is drawn. Yamaha could simplify the process still further by providing an app or plug-in to translate and load English (Japanese) lyrics directly to an embedded NSX-1 or DAW. This would eliminate a few manual steps.
Overall, pre-loaded lyrics coupled with realtime performance makes for a more engaging and immediate musical experience than working with the full Vocaloid editor. If Yamaha is thinking about an eVocaloid performance instrument, this is the way to go!
The pre-loaded lyric approach beats one early attempt at realtime Vocaloid performance as shown in this You Tube video. In the video, the musician plays the melody with the right hand and enters katakana with the left hand. I would much rather add modulation and navigate through the lyrics with the left hand. This is the approach taken for the Vocaloid keytar shown on the Yamaha web site.
Here is a list of my blog posts about Pocket Miku and the Yamaha NSX-1:
I hope that my experience will help you to explore Pocket Miku and the Yamaha NSX-1 on your own!
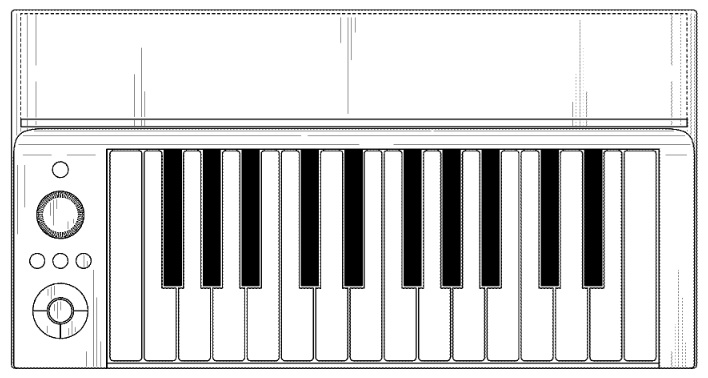
Before leaving this topic, I would like to pose a speculative question. Is the mystery keyboard design shown below a realtime eVocaloid instrument? (Yamaha U.S. Patent number D778,342)
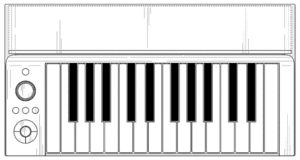
The E-to-F keyboard just happens to coincide with the range of the human voice. Hmmmm?
Copyright © 2017 Paul J. Drongowski