Yamaha develop a wide range of keyboard products from low-cost entry-level ‘boards to high-end synthesizers and digital workstations (AKA “arrangers”).
Within a market segment, the engineering challenge is to develop, manufacture and test a product with the desired feature set at the target selling price. I won’t discuss profit margin here since no one really knows, but Yamaha. We do know, however, that amortized non-recurring and recurring costs must be low enough to produce a significant return. Cost sensitivity is simply a day-to-day reality.
The entry-level segment is the most cost-sensitive segment because most customers in this segment are looking for an inexpensive keyboard with basic functionality. Think “Parents buying a first keyboard for a kid who may walk away from the whole thing in a week or two.” The entry-level segment outsells the mid- and high-end portable keyboard segment by nearly 2 to 1:
Category Units Retail value
----------------------------- --------------- -------------
Acoustic guitars 1,499,000 units $678,000,000
Electric guitars 1,132,000 units $506,000,000
Digital pianos 135,000 units $165,000,000
Keyboard synthesizers 81,000 units $104,000,000
Controller keyboards 160,000 units $ 32,000,000
Portable keyboards under $199 656,000 units $ 64,000,000
Portable keyboards over $199 350,000 units $123,000,000
Total portable keyboards 1,006,000 units $187,000,000
Sales Statistics for 2014, USA market
Synth fanatics should note that although the average selling price (ASP) is higher for synths, the portable keyboard segment moves a much higher number of units. Fortunately, for manufacturers playing in the entry-level portable keyboard space, volume is relatively high and non-recurring cost can be laid off across a larger number of units than synths.
The entry-level segment has one other important driver — the desire for portable, battery operation. This design consideration limits the amount of electrical power available for computation and thus, limits the amount of computational capacity itself. Some dynamic power can be bought back through lower CPU clock speeds. Folks accustomed to giga-Hertz CPUs may be shocked to see such low clock speeds! Lower clock speeds simplify cooling and reduce overall weight by eliminating heat sinks and cooling fans.
LSI vs. commodity
Yamaha perceive their proprietary expertise in large scale integration (LSI) as a competitive advantage. Although Yamaha exploit commodity components where possible, tone generation and digital signal processing (DSP) are performed in proprietary hardware.
User interface and control (e.g., USB communications, MIDI, LCD, etc.) are a good fit with commodity CPU technology. Yamaha — and Roland — have a long history with H8 and SH architecture CPUs from Hitachi, now Renesas. Early products employed H8 microcontrollers for host CPU functions. Yamaha eventually migrated to the “Super H” reduced instruction set computer (RISC) family. (In 2011, Renesas announced the end of the H8 line.)
Yamaha have a considerable investment in software built and tuned for the SH family. Thus, migration to a new commodity architecture (ARM) is a pretty big deal with a high internal cost. Yamaha have adopted ARM for panel scanning/control in Reface and are using ARM processors for host computation in Montage and Genos. Time and experience will show if ARM is adopted in the entry- and mid-range segments, too.
Old faithful
Yamaha’s entry-level models rely on “old faithful,” the SWL family of proprietary Yamaha processors. The SWL is used in all entry-level models — a good way to drive volume manufacturing of a custom part. The SWL family has undergone several revisions over the years. I don’t intend to recount that history here.
The SWL01U was used in many products including the PSR-E443. The external clock crystal oscillates at 16.9344MHz yielding an internal clock speed of 33.8688MHz by scaling. The relatively low clock speed reduces heat and power consumption. The following diagram shows the typical “compute complex” in an entry-level keyboard. [Click to enlarge.]
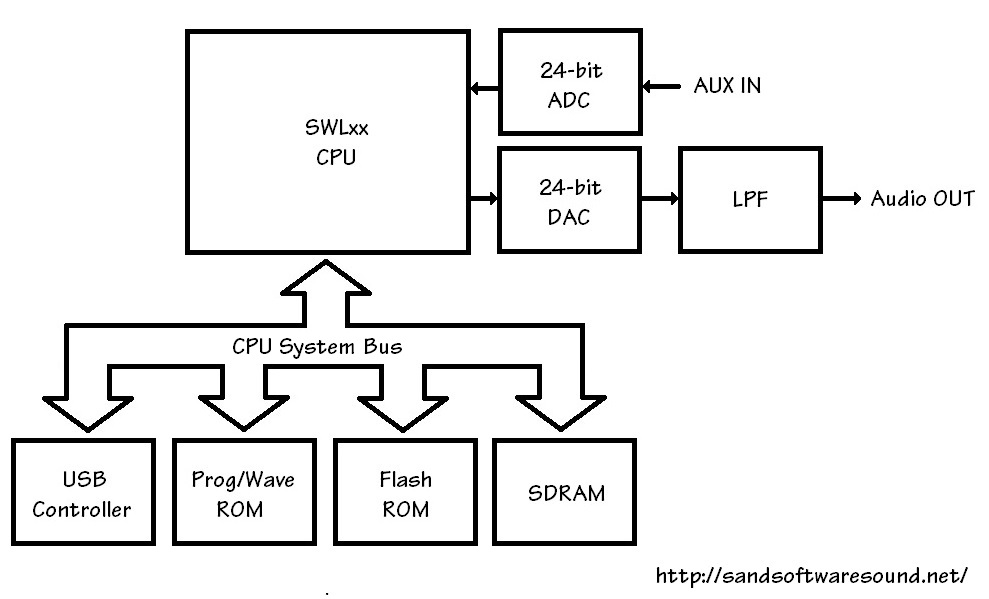
The structure in the diagram is generic across Yamaha entry-level products. If you dive into the service manual for a specific entry-level keyboard, you’re likely to find a “compute complex” like this generic one although memory capacities and such are model specific.
The SWL01U provides a CPU bus to which a USB controller (optional), program/wave ROM, flash ROM and SDRAM are attached. The SWL01 has many on-board interfaces: keyboard scanning, LED/LCD interface, bit-serial audio (ADC, DAC), control knob sensing, etc. The SWL01U has an integrated USB controller which can be deployed in ultra low-cost, minimum component count designs.
The SDRAM is, of course, read/write working memory. The flash ROM retains user data when power is turned off.
The program and waveform data are stored in the same physical memory component. In the case of the PSR-E443, the prog/wave memory is a 16MByte parallel NOR flash memory. The factory sound set, therefore, is smaller than 16MBytes. Panel voices, the XGlite sound set, and drum kits are crammed into this small memory along with the E443’s software.
The SWL01U integrates 32 tone generation channels and relatively “lite” DSP effects (reverb, chorus and flanger). I have not had the chance to browse the service manual for the PSR-E453 (or E463). E453 polyphony increased to 48 voices and the DSP effect types got a modest bump. I expect to find a new, updated member of the SWL family in these newer keyboards.
Anyone modestly familiar with microcomputer systems will look at the diagram above and say, “It’s just a computer system,” and they would be right. The simplicity of the system — and its low cost — severely limit tone generation and effect processing, however. The bottleneck is the shared system bus. All traffic must cross this bus whether it is instructions for scanning the keyboard matrix, waveform samples for tone generation, or working data for DSP effects. There is only so much bus (memory) bandwidth and it must be split several ways.
We often think of tone generation as compute-limited. Tone generation may be memory (or bus) bandwidth limited, too. Each mono channel of tone generation must read 88,200 bytes per second:
44,100Hz * 2bytes = 88,200 bytes per second
For 32 tone generation channels, total required bandwidth is :
88,200 bytes per second * 32 channels = 2,822,400 bytes per second
This rate must be guaranteed in order to avoid audible artifacts. (Tone generation reads are probably given highest priority by the hardware.)
The system bus does not operate at the same speed as the CPU clock. Assuming 2 clocks per bus operation (conservative estimate), 2.8MBytes/second is a significant fraction of available system bus bandwidth (17 percent). The number of channels cannot be increased without affecting the latency of host operations such as key scanning and real-time player control (e.g., front panel knobs).
Who’s counting?
Entry-level products have a low component count thanks to all of the functionality integrated into the SWL. Low component count has many benefits including smaller printed circuit boards (PCB), lower power, fewer solder connections to go wrong during manufacturing, smaller chassis, etc.
The SWP01U has 176 pins around a modest-sized, quad flat surface mount package. By putting all memory traffic on the CPU bus, i.e., not using a dedicated memory channel for waveform samples, Yamaha have achieved a relatively low pin count. [I never thought I would ever refer to 176 pins as “relatively low.”] Other Yamaha solutions have a much greater pin count due to separate dedicated memory channels. Those solutions, however, deliver a much higher level of performance and polyphony. More about this in future posts.
What’s up, clock?
What’s up with those clock speeds? Why not something “even,” like 16MHz?
Turns out, 16.9344MHz is a multiple of the sample playback frequency:
16,934,400Hz = 44,100Hz * 24bits * 16
The SWL generates the sample clock for the ADC and the DAC.
The PSR-E443’s ADC is a Texas Instruments PCM1803ADBR 24-bit analog to digital converter. A note in the schematic states “MCLK=768fs, fs=44.1kHz, 24-bit left justified, HPF on, Slave Mode.” 768*fs is 33.8688MHz which is exactly the CPU clock frequency.
The PSR-E443’s DAC is a Cirrus Logic (Wolfson) WM8524CGEDT/R 24-bit digital to analog converter. A note in the schematic states “SYSCLK=33.8688MHz (768fs), BCLK=2.8224Mhz (64fs), WCLK=44.1kHz (1fs), 24-bit left justified.”
You can find the datasheets for the ADC and DAC by searching the Web.
The PCM803A and WM8524 support three audio formats: left justified, right justified and I2S. The formats and clock scheme are rather common and standard, and are supported by most commodity audio ADC and DAC components. The SWL processor, ADC and DAC remain in synch because the CPU clock and the sample clock are one and the same.
So long!
I hope this blog post has given some insight into the design of entry-level musical instrument keyboards.
Copyright © 2018 Paul J. Drongowski