Performance measurement and tuning experiments with Raspberry Pi 4 are well-underway. Here are a few quick observations and tips.
Linux provides two entries into performance measurement: Performance Events for Linux (PERF) and the kernel performance counter interface (perf_event_open()). PERF is an easy-to-use tool suite and is the best place to start explorations. If you want to measure an application without modifying its code, this is for you.
PERF is built on the kernel performance counter interface. The interface consists of two calls: perf_event_open() and its associated ioctl() functions. The kernel interface is suitable for self-monitoring, that is, adding calls to an application in order to measure its internal operation. Performance counters provide two modes of operation: counting and sampling. Counting mode is most appropriate for self-monitoring. I’m currently writing code that makes self-monitoring a bit easier and hope to post the code when it’s ready.
In the meantime…
Installation
PERF and perf_event_open support are not usually installed with your typical Linux distribution. Originally, PERF was available solely as part of the Linux tools package. Well, it seems like somewhere along the way, Ubuntu and Debian diverged. Ubuntu installs PERF with Linux tools:
sudo apt-get install linux-tools-common
sudo apt-get install linux-tools-common-$(uname -r)
As PERF depends heavily upon kernel facilities and interfaces, you should install the version of PERF that matches the installed kernel.
Raspberry Pi OS (once known as Raspian) is a Debian distro. Shucks, wouldn’t you know it, Debian installs PERF differently:
sudo apt install linux-perf
There are different packages for buster and stretch (the current versions of Raspberry Pi OS and Debian at the time of this writing).
https://packages.debian.org/buster/linux-perf
https://packages.debian.org/stretch/linux-perf
Installing on buster produces output like:
XXX@raspberrypi:~ $ sudo apt install linux-perf
password for XXX:
Reading package lists… Done
Building dependency tree
Reading state information… Done
The following additional packages will be installed:
linux-perf-4.9
Suggested packages:
linux-doc-4.9
The following NEW packages will be installed:
linux-perf linux-perf-4.9
0 upgraded, 2 newly installed, 0 to remove and 107 not upgraded.
Need to get 1,275 kB of archives.
After this operation, 2,735kB of additional space will be used.
Do you want to continue? [Y/n]
Versioning gotcha
And, of course, it’s never that simple. My version of Raspberry Pi OS (buster) is expecting PERF version 5.4. When you enter “sudo perf list” or any other PERF command on the command line, the shell runs the script /usr/bin/perf. The script checks the version of PERF against the kernel and complains when versions don’t match. The Debian install pulled version 4.9, not 5.4.
Rather than sort out versioning, I’ve been entering “perf_4.9” instead of “perf“. This work-around bypasses the perf script which checks versions. Since PERF is now fairly mature, it all seems to work. At some point, I’ll sort out the versioning situation and install 5.4. In the meantime, full steam ahead!
Getting started
Here’s a few PERF commands to get you started:
perf stat --help
perf list sw
perf stat
perf top -a
perf top -e cpu_clock
perf record
perf report
The stat approach uses counting mode to measure software and hardware events triggered by an application program (“<cmd>”). The top approach displays event counts dynamically in real-time like the ever-popular “top” utility program. The record and report approach uses sampling to produce performance reports and profiles.
For additional usage information, check out the Linux performance analysis tutorial. There are several other fine tutorials and helpful sites on the Web. Many of the tutorials show use on x86 (Intel and AMD) systems, not Raspberry Pi and ARM. For that, I recommend my own three part tutorial:
- Part 1 demonstrates how to use PERF to identify and analyze the hottest execution spots in a program. Part 1 covers the basic PERF commands, options and software performance events.
- Part 2 introduces hardware performance events and demonstrates how to measure hardware events across an entire application.
Part 3 uses hardware performance event sampling to identify and analyze hot spots within an application program.
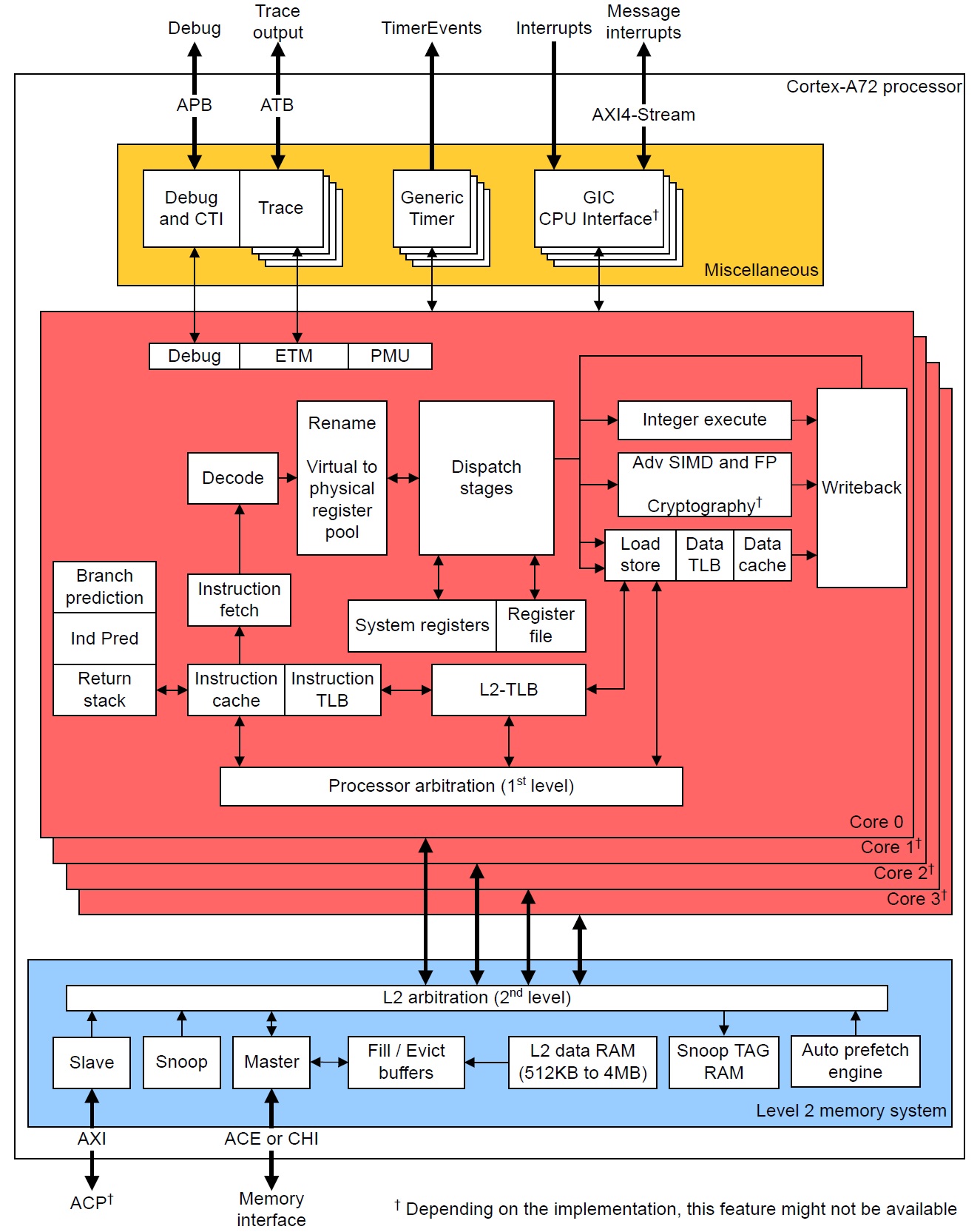
In addition to usage, I offer information and guidance concerning ARM micro-architecture. This information is especially helpful when you get into hardware performance events. Check out my summaries of the ARM11 and ARM Cortex-A72 micro-architectures. ARM11 covers Raspberry Pi models 1, 2, and 3 (BCM2835 and BCM2836), while the Cortex-A72 summary covers the Raspberry Pi 4 (BCM2711).
Other helpful on-line resources are:
- “PERF Examples” by Brendan Gregg.
- Using the perf utility on ARM, by Stefan.
- “Enabling Raspberry Pi Performance Counter Support on Linux perf_event”, by Chad Paradis and Vincent Weaver, UMaine ECE Tech Report 2014-2.
Paranoia!
Performance measurement is fraught with security issues and holes. The kernel developers implemented a control flag file, /proc/sys/kernel/perf_event_paranoid which sets the level of access and vulnerability when taking measurements. Quoting the Linux man page:
The perf_event_paranoid file can be set to restrict access
to the performance counters.
2 allow only user-space measurements (default since
Linux 4.6).
1 allow both kernel and user measurements (default
before Linux 4.6).
0 allow access to CPU-specific data but not raw
tracepoint samples.
-1 no restrictions.
The existence of the perf_event_paranoid file is the
official method for determining if a kernel supports
perf_event_open().
If you’re operating in a fairly closed, single-user environment, then set the content of the file to 0 or -1.
Read the perf_event_open() man page
I recommend reading the perf_event_open() man page. If you’re just starting your journey into performance measurement, you will be overwhelmed by the detail at first. However, just let the information wash over you and know that it’s there. The tutorials don’t always mention the perf_event_paranoid flag and other low-level details. Reading the man page should help you across future stumbling blocks and will enhance your understanding of events, counting and sampling.
Want to learn more about Raspberry Pi 4 (Cortex-A72 / Broadcom BCM2711) performance tuning? Please read:
- ARM Cortex-A72 tuning: IPC
- ARM Cortex-A72 tuning: Data access
- ARM Cortex-A72 fetch and branch processing
- ARM Cortex-A72 execution and load/store
Copyright © 2020 Paul J. Drongowski