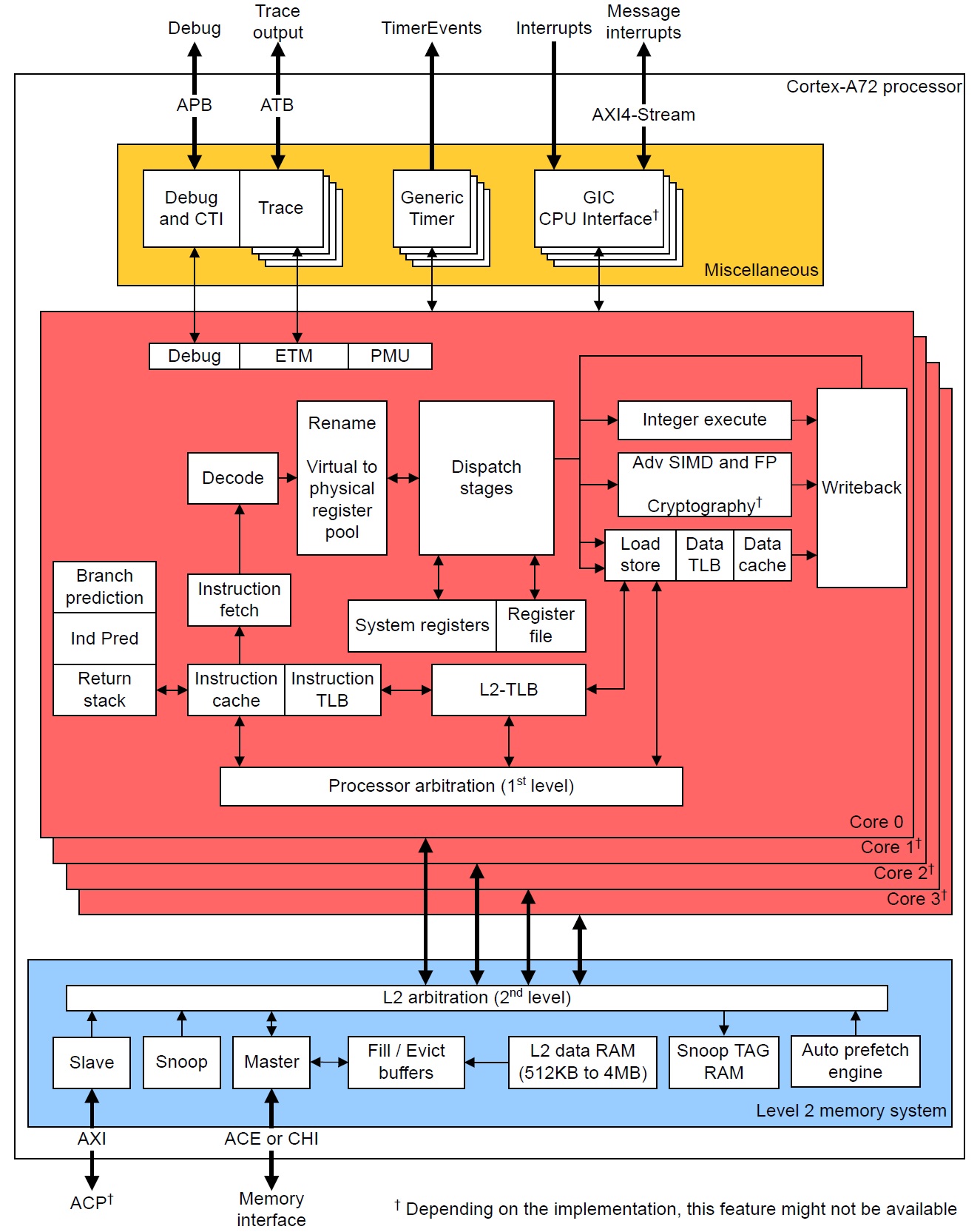
I hope you had an opportunity to read about ARM Cortex-A72 fetch and processing. ARM Cortex-A72 is the high performance application core in the Broadcom BCM2711, also known as the Raspberry Pi 4. In this post, I’m going to continue my exploration of the A72 micro-architecture, concentrating on the execution units and load/store operation.
Execution pipelines
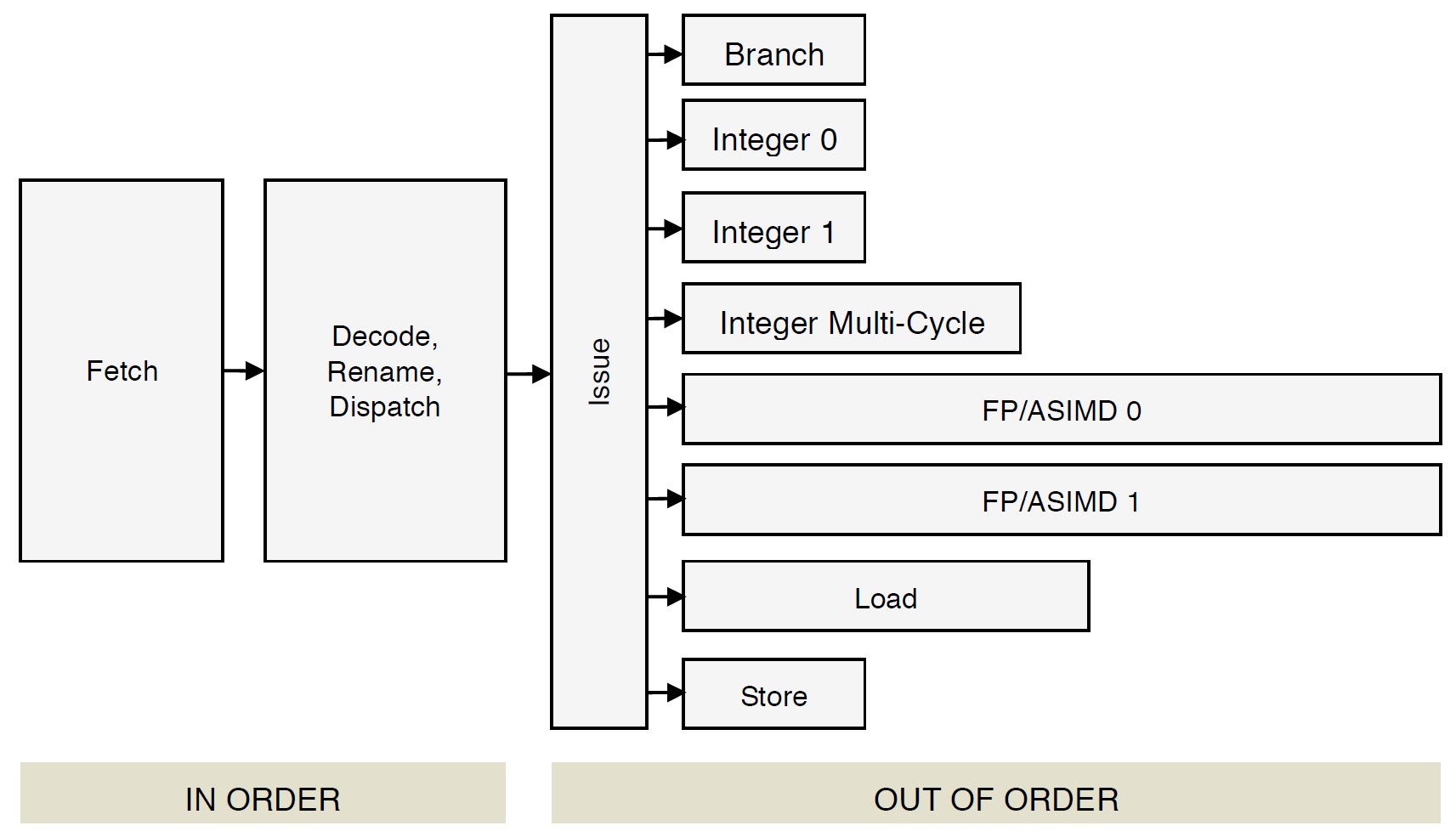
Cortex-A72 has eight independent execution units (pipelines):
- Branch: Branch micro-ops
- Integer 0: Integer ALU micro-ops
- Integer 1: Integer ALU micro-ops
- Integer Multi-Cycle: Integer shift-ALU, multiply, divide, CRC and sum-of-absolute differences micro-ops
- FP/ASIMD 0: ASIMD ALU, ASIMD misc, ASIMD integer multiply, FP convert, FP misc, FP add, FP multiply, FP divide and crypto micro-ops
- FP/ASIMD 1: ASIMD ALU, ASIMD misc, FP misc, FP add, FP multiply, FP square root and ASIMD shift micro-ops
- Load: Load and register transfer micro-ops
- Store: Store and special memory micro-ops
The Cortex-A72 front-end puts micro-ops into per-pipe issue queues which, in turn, feed the execution units. There are eight issue queues. The queues have eight entries each except the branch queue, which has ten entries (66 queue entries total like the old Cortex-A57). The queues provide rate-balancing between the core front-end (i.e., the instruction/micro-op stream) and the execution units. The queues allow greater parallelism between units, too, letting each pipeline run at its own independent single- or multi-cycle speed.
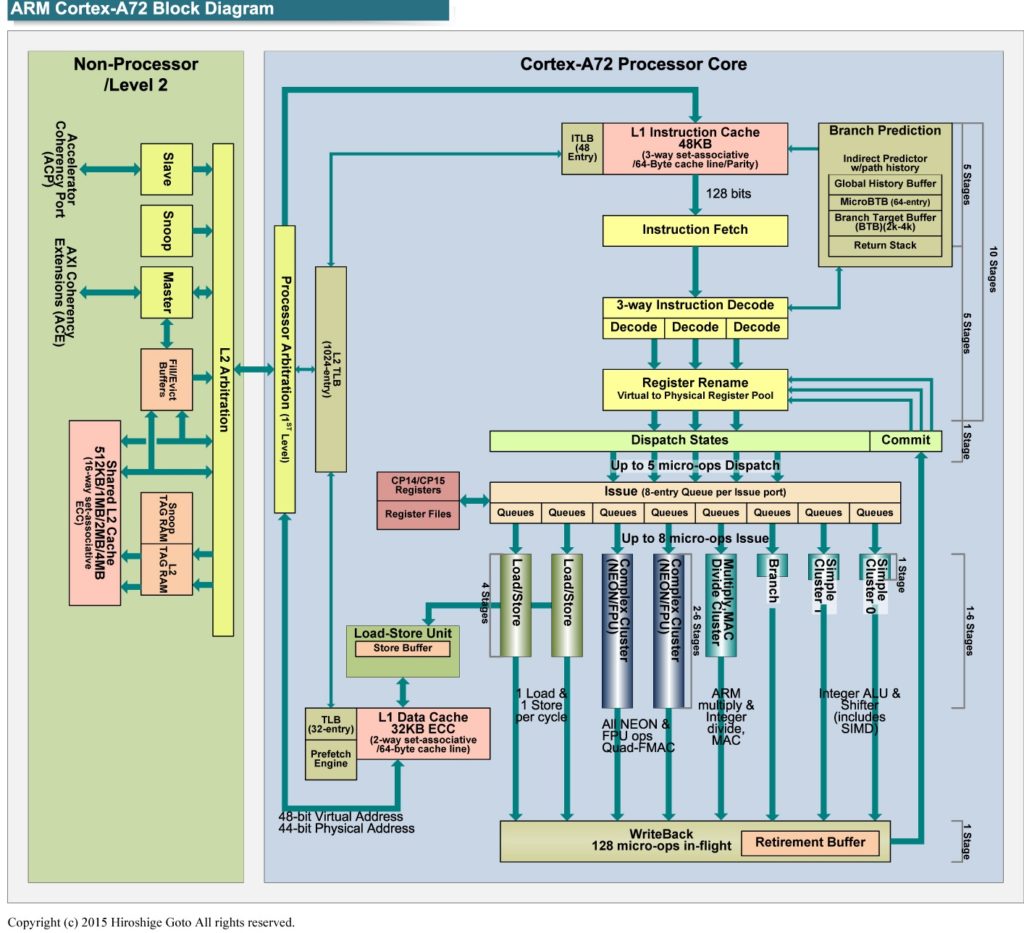
The branch and integer pipes are very fast, each pipe executing a micro-op in a single processor cycle. The integer pipelines have multiple, zero-cycle forwarding datapaths. These paths, sometimes called “by-passes,” send intermediate results directly to stages (computations) needing the result right darned now without writing the result into the rename register file first.
The integer multi-cycle pipe handles integer micro-ops which require 2 or more processor cycles for execution. Shift operations are relatively fast: 2+ cycles. Integer multiplication has a 3 to 5 cycle latency. Integer divide is relatively slow taking anywhere from 4 to 20 cycles. Multiplication can be accelerated through dedicated combinational logic; division is sequential by nature and requires many steps.
The FP (floating point) and ASIMD (Advanced Single Instruction Multiple Data) units perform floating point and SIMD computations. Both units are generalist and perform commonly occurring FP operations: FP ADD, SUB, MUL, NEG, ABS, MAX, MIN, etc. Execution latency varies from 3 to 4 cycles for these basic operations. The FP pipes support late forwarding of FP MUL products to FP multiply-accumulate micro-ops, letting FP multiply-accumulate complete in 6 cycles.
Each FP unit is a specialist, too:
- FP/ASIMD 0: FP CONVERT, ROUND, DIV, CRYPTO
- FP/ASIMD 1: FP COMPARE, SQRT
FP divide and square root operations are performed using iterative algorithms. Only one FP DIV or SQRT operation at a time may execute in a pipe. Latencies are long: 6 to 18 cycles for DIV and 6 to 32 cycles for SQRT, depending upon FP datatype.
Please see the ARM Cortex-A72 Software Optimization Guide for detailed instruction timing, pipe assignment and ASIMD operation.
Load and store micro-ops are executed by the load and store units. The load and store units are mutually independent. One load and one store micro-op can execute each processor cycle. (Load and store are discussed below.) Load and store micro-ops issue speculatively. Under speculative execution, a load or store may reside on a correctly predicted branch path (the correct path) or an incorrectly predicted branch path (the wrong path). Loads, stores and associated data on a wrong path must be discarded. Store operations are buffered (wait) until they are determined to be on the correct path and are committed architecturally to primary memory.
Memory hierarchy
As I mentioned in my Cortex-A72 overview, the Raspberry Pi 4 (Broadcom BCM2711) has a four level memory hierarchy:
Register Fast, but small
|
Level 1 caches
|
Level 2 cache
|
RAM Big, but slow
The RPi4 has four A72 cores. Each core has a register file and level 1 instruction and data caches. The four cores share a single unified level 2 cache and primary memory (RAM).
The register file is the fastest, but has the smallest capacity. Registers are read or written in a single processor cycle. RAM has the most capacity, but is relatively slow. RPi4 primary memory is LPDDR4-3200 SDRAM:
| Memory array clock | 200 MHz |
| Prefetch size | 16n |
| I/O bus clock frequency | 1600 MHz |
| Data transfer rate (DDR) | 3200 Mb/s |
| Memory accesss bandwidth (MABW) | 12.8 GB/s |
MABW above is peak. Memory bandwidth measurements using RAMspeed/SMP indicate actual RPi4 model B bandwidth is approximately 4.4 GB/s. (RAMspeed/SMP reads/writes memory in 1MB blocks.)
The following table summarizes Cortex-A72 cache characteristics:
| L1I cache capacity | 48KB |
| L1I cache organization | Per-core, 3-way set associative, 64B line |
| L1D cache capacity | 32KB |
| L1D cache organization | Per-core, 2-way set associative, 64B line |
| L2 cache capacity | 1MB |
| L2 cache organization | Shared, 16-way set associative, 64B line |
Data accesses are handled by the Level 1 Data (L1D) cache. Instruction fetches are handled by the Level 1 Instruction (L1I) cache. The Level 2 (L2) cache is unified, handling both data and instructions. The Raspberry Pi BCM2711 ARM Peripherals manual states the following caveat with respect to the L2 cache:
BCM2711 provides a 1MB system L2 cache, which is used primarily by the GPU. Accesses to memory are routed either via or around the L2 cache depending on the address range being used.
Thus, application programs should not expect to receive a performance assist from the L2 cache! The VideoCode GPU accesses L2 cache through the Cortex-A72 ACP/AXI interface.
The L1D cache load-to-use latency is 4 cycles when the load hits in the L1D cache. The Level 2 (L2) cache load-to-use latency is 9 cycles when the load hits in the L2 cache.
A read access (e.g., a data load or instruction fetch) first tries the appropriate level 1 cache (Load: L1D cache, Fetch: L1I cache). If it finds the requested item in the level 1 cache — a hit — the item is sent to either the rename registers (for loads) or the instruction decoder (for fetches). Load data may also be sent through a bypass to an execution stage (micro-op) awaiting the incoming data.
If the read access misses the level 1 cache, the request is sent (optionally) to the unified L2 cache. If the requested item is found in L2 cache, the cache line containing the item is written into the level 1 cache, thereby replacing one of the existing lines. This operation is called a “refill.” If the line to be replaced is dirty (modified), then the old value is evicted and is written to primary memory. The requested item is selected from the incoming cache line and is routed to the appropriate destination (i.e., functional unit or instruction decoder).
If the read access misses (or optionally, bypasses) the L2 cache, the 64 byte line containing the item is read from primary memory. The incoming line is written to the level 1 cache (a refill) and (optionally) the L2 cache. Again, dirty lines are evicted.
Instruction and data bytes are read, written and transferred in 64-byte chunks (lines). This is true even if a load instruction requests a single byte from memory. Application programs should strive to use each entire cache line completely before moving on to the next line. Programs that exploit spatial and temporal locality perform better. Programmers need to pay careful attention to algorithm selection, data structure/layout and memory access patterns in order to make good, efficient use of data caching.
The description of Cortex-A72 cache operation above is simplified. Consider, for example, memory transaction types. Memory attributes within the Memory Management Unit (MMU) and page tables determine memory transaction types for each memory region:
- Write-Back Read-Write-Allocate
- Write-Back No-Allocate
- Write-Through
- Non-cacheable
- Device
Memory transaction type affects cache behavior.
Write-Back Read-Write-Allocate is the most common and highest performing memory type. Incoming lines are written to the L1D cache and the read (or write) completes from the L1D cache. A store that hits a Write-Back cache line does not update main memory.
Write-Back No-Allocate does not write an incoming line to L1D cache. This prevents cache pollution when accessing large, one-time use data structures.
Non-cacheable memory bypasses both the level 1 caches and L2 cache. Requests go directly to primary memory. The Cortex-A72 treats Write-Through memory as Non-cacheable.
Instruction fetch (more details)
Instruction fetches are speculative and there is no guarantee that fetched instructions are executed. Instructions are aggressively prefetched pursuing either sequential execution flow or branch targets based on path prediction.
The L1I cache is fed by three fill buffers that hold instructions from either the unified L2 cache or primary memory. The fill buffers are non-blocking. A line may remain in a fill buffer until it is transferred to the L1I cache or discarded. Primary memory regions may be marked as non-cacheable regions or the L1I cache may be disabled, and incoming lines are not written to the L1I cache. A line is not committed to the L1I cache unless it is demanded by a fetch. The hardware also has an L2 instruction prefetcher.
Cortex-A72 treats the preload instruction cache instruction (PLDI) as a NOP.
Memory Management Unit
The Memory Management Unit (MMU) performs virtual to physical address translation and enforces secure, restricted access to memory regions. As to security, suffice it to say that the MMU restricts access by Address Space Identifier (ASID) and Virtual Machine Identifier (VMID). These concerns are addressed by the operating system and are generally transparent to application programmers. [And I won’t be dealing with access control here.]
| Address type | AArch64 | AArch32 |
|---|---|---|
| Virtual address (VA) | 48 bits | 32 bits |
| Physical address (PA) | 44 bits | 40 bits |
The Cortex-A72 hardware supports 4KB, 64KB and 1MB page sizes. The Raspberry Pi Operating System (formerly known as “Raspbian”) organizes primary memory into 4KByte pages. [Huge pages must be enabled in the kernel and I will assume that it’s 4KB all the way on RPi4.] The operating system maintains page tables that specify the physical location of application program pages (both instructions and data).
Application programs use virtual addresses to identify instructions and data items. Conceivably, hardware could use memory-resident page tables to map a virtual address to its corresponding physical address. This approach is way too slow to be practical. Better, the Cortex-A72 maintains page (address) mapping information in a multi-level, hierarchical memory system:
Level 1 TLB Fast, but small
|
Level 2 TLB
|
RAM Big page tables, but slow
The TLB structure is separate from the register/cache/memory hierarchy and it operates independently. The organizing principle is the same — most recent and frequently used mappings reside in fast memory and big page tables reside in slow primary memory.
“TLB” is the acronym for “translation lookaside buffer.” A TLB is an array where each entry describes the mapping from a virtual page to a physical page. Internal operation of a TLB is similar to a data cache. The following table summarizes Cortex-A72 TLB characteristics:
| L1I TLB capacity | 48 entries |
| L1I TLB organization | Fully associative |
| L1D TLB capacity | 32 entries |
| L1D TLB organization | Fully associative |
| L2 TLB capacity | 1024 entries |
| L2 TLB organization | 4-way set associative |
The L1I and L2D TLBs support 4KB, 64KB, and 1MB page sizes. The L2 TLB supports 4KB, 64KB, 1MB and 16MB page sizes. (Also, 2MB and 1GB using AArch32 long descriptor format translation.) Alas, Raspberry Pi OS uses 4KB pages.
TLB operation is similar to caching. Address translation is first tried in the L1I TLB (fetches) or L1D TLB (loads and stores). If the translation information is found (a hit), the physical address is returned in one cycle. Access permission is checked at the same time.
If translation misses in a level 1 TLB, address translation is attempted in the main L2 TLB. If the translation information is found, the physical address is returned (after one or more cycles).
If translation misses in the L2 TLB, the MMU performs a hardware translation table walk. (Page tables have a fairly complicated structure which is beyond the scope of this discussion.) Because page tables reside in slow primary memory, a hardware translation table walk takes a relatively long time to complete with respect to an L2 TLB look-up.
If the required page is not in memory and is on the RPi OS swap device, the operating system reads the page into primary memory before attempting re-translation. These exceptions, page faults, are the slowest of all and they should be avoided like the plague.
Once again, program performance depends up good temporal and spatial locality, albeit locality at the page level. An application program can touch as many as 32 different data pages without triggering an L1D TLB refill:
32 L1D TLB entries * 4 KBytes/page = 128 KByte data working set
This is a modest-sized working set of pages, and like cache line strategy, a program should make maximal, efficient use of a page working set before demanding new page translation information from the L2 TLB. The L2 TLB supports a larger combined data/instruction working set:
1024 L2 TLB entries * 4 KBytes/page = 4 MByte total working set
The L2 TLB footprint (working set size) is larger. However, the L1D TLB and the L1I TLB compete for page translation entries in the unified L2 TLB.
As to data-page utilization, data structure layout and access pattern come into play once again. A program should work as much as possible within the current working set before moving to pages outside the current set. Random access within a big heap pays a penalty when heap items are distributed across many pages (i.e., when the working set exceeds 32 pages).
With respect to L1I TLB utilization strategy, frequently executed, related code should reside within the same page or just a few pages. Related code which is spread across many pages (i.e., a large instruction working set) will jump between pages and possibly cause L1I TLB or L2 TLB refills.
The above description of the translation process is simplified. For example, access is checked against page permissions, etc. and violations are reported after aborting offending translation and instruction. I tried to focus mainly on performance-related concerns of interest to application programmers.
Load and store operations
After absorbing all of that, let’s pick up a few additional odds and ends about load and store operations.
Cortex-A72 memory operations are weakly ordered. They may be performed out-of-order as long as data dependencies are honored. Due to the weak ordering, explicit synchronization barriers are needed in circumstance where strong ordering is required. There are four kinds of barriers:
- Instruction Synchronization Barrier (ISB)
- Data Synchronization Barrier (DSB)
- Data Memory Barrier (DMB)
- Load-Acquire (LDAR) and Store-Release (STLR)
Please see the Programmer’s Guide for ARMv8-A for further details.
More generally important to application programmers is data alignment. Naturally aligned data is accessed faster than unaligned data, especially unaligned data items that cross cache line boundaries. The following table summarizes alignment requirements:
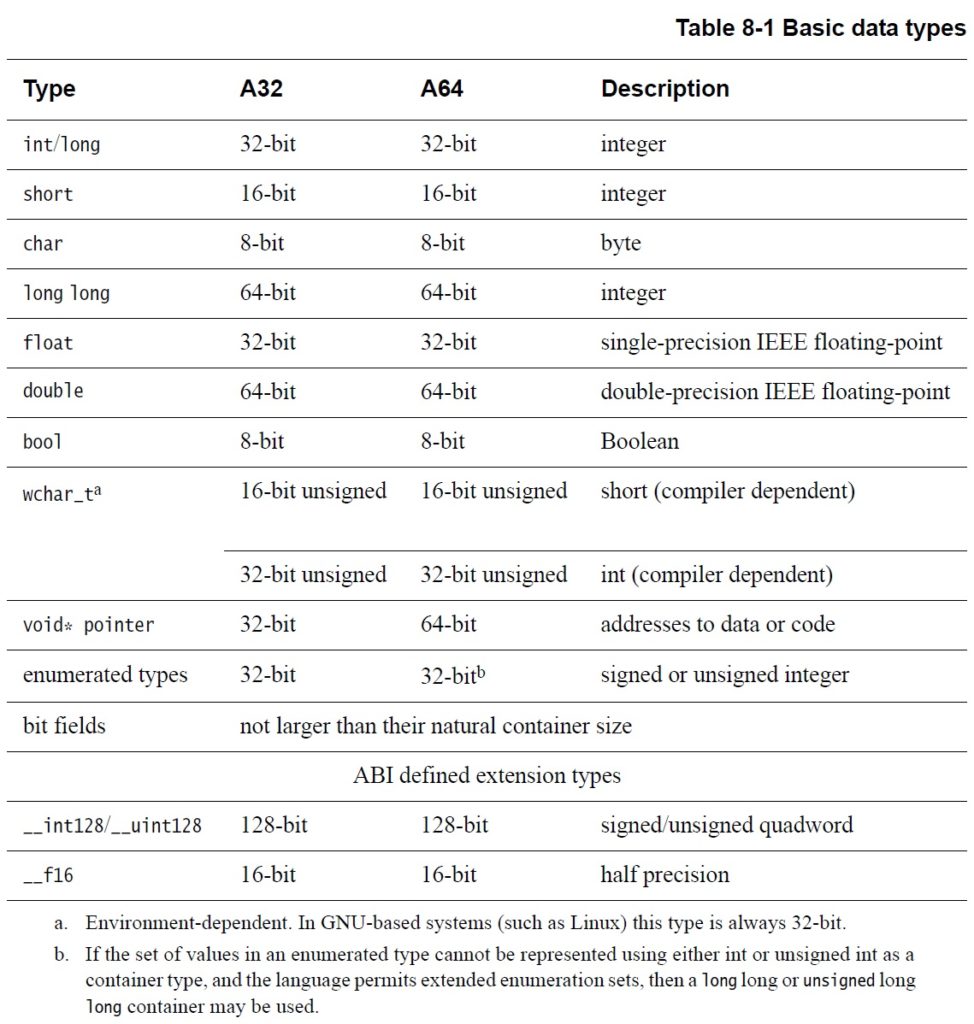
Load operations should not cross 64-byte, cache line boundaries. Store operations should not cross 16-byte boundaries.
As a general program design principle, computations proceed as fast as data items can stream from primary memory, and secondarily, as fast as results can stream back to primary memory. Data prefetching increases the speed of incoming data stream(s). The programmer or compiler should schedule load operations further ahead of instructions which consume the incoming data item. Ideally, other independent instructions are scheduled and executed ahead of the consuming load thereby overlapping useful computation with load latency (4 cycles from the L1D cache at a minimum).
A program may signal the need for a data item through an explicit prefetch instruction. The A72 supports three instruction prefetch hint instructions: PLD, PLDW, and PRFM. These are only hints and may be ignored. The PLD and PLDW instructions allocate a line in the Level 1 Data cache. Prefetch from Memory (PRFM) hints that data from a specific address will soon be needed. If accepted, these hints can bring in a data item (cache line) before it is required.
Programmers may further manage data cache contents via non-temporal load and store instructions (LDNP and STNP). These instructions hint that caching is not useful for data at an address, thereby preventing unnecessary cache pollution. Non-temporal load and store instructions may require explicit load barriers. (See the Programmer’s Guide for ARMv8-A for more details.)
The Cortex-A72 hardware has a load-side prefetcher which dynamically analyzes memory access patterns. Based on its analysis, the load-side prefetcher brings data into either the L1D cache, the L2 cache, or both. The hardware also has a store-side prefetcher which brings data into the L2 cache.
Outgoing data streams benefit from write combining which merges data from multiple store operations into a single memory write access.
Outstanding read and write requests (i.e., pending requests to primary memory) wait in the Fill/Eviction Queue (FEQ). The Cortex-A72 has a configurable FEQ: 20, 24, or 28 entries. The A72 write issuing capability is 16, that is, up to 16 writes may be outstanding at any time. The read issuing capability is 19, 23, or 27 depending upon FEQ configuration (capacity). L2 prefetch is throttled based on the FEQ occupancy count. [Extra credit: What is the specific Raspberry Pi 4 FEQ configuration and occupancy threshold?]
One important simplification in the cache discussion is cache coherency. Most application programmers needn’t worry about cache coherency. However, if you are writing a program with multiple, co-operating threads that actively share memory locations or regions, you should MOESI over to the ARM Cortex-A72 Technical Reference Manual (TRM) and read up on the details. The A72 Snoop Control Unit (SCU) uses a hybrid protocol (MESI+MOESI) to maintain coherency between the per-core L1 data caches (MESI) and the common L2 cache (MOESI). “MESI” and “MOESI” refer to the coherency status of each cache line:
- Modified (M)
- Owned (O)
- Exclusive (E)
- Shared (S)
- Invalid (I)
The BCM2711 employs an Advanced Microcontroller Bus Architecture (AMBA) Advanced xExtensible Interface (AXI) bus interface. Broadcom does not specify if either AXI Coherency Extensions (ACE) or the Coherency Hub Interface (CHI) are supported. (Man, these acronyms stack up!) Since ACE and CHI are intended for SMP processor clusters (e.g., big.LITTLE) these features may have been left out or disabled.
If you do care about cache coherency, please be aware that load data may be sourced from a remote L1D cache as well as the shared L2 cache or primary memory.
Sources
Before closing, I want to offer a few words about my sources. My primary resources are:
- ARM Cortex-A72 Technical Reference Manual (TRM)
- ARM Cortex-A72 Software Optimization Guide
- ARM Programmer’s Guide for ARMv8-A
- BCM2711 ARM Peripherals
These resources are authoritative. I also relied upon ARM’s own briefings and presentations about Cortex-A72 as found on the Web. I tried to verify Web sources and briefings against the written TRM and programmer guides.
In closing
Hopefully, my write-ups will help developers tune their programs for ARM Cortex-A72. If you’re just getting started with performance tuning, I would first concentrate on cache- and page-friendly algorithms, data structures and access patterns. Fill buffers, FEQ, memory ordering, and memory transaction types are esoteric subjects for most application programmers.
Want to learn more about Raspberry Pi 4 (Cortex-A72 / Broadcom BCM2711) performance tuning? Please read:
If you’re interested in early model Raspberry Pi, I wrote several posts about micro-architecture, performance measurement and performance events:
- ARM11 micro-architecture
- ARM11 (RPi gen 1) memory hierarchy
- Performance measurement and tuning (ARM11)
- Performance Events for Linux (PERF) tutorial
There you will find general principles and techniques that apply to Raspberry Pi 4 although some details (e.g., cache and TLB capacity) differ.
Copyright © 2021 Paul J. Drongowski