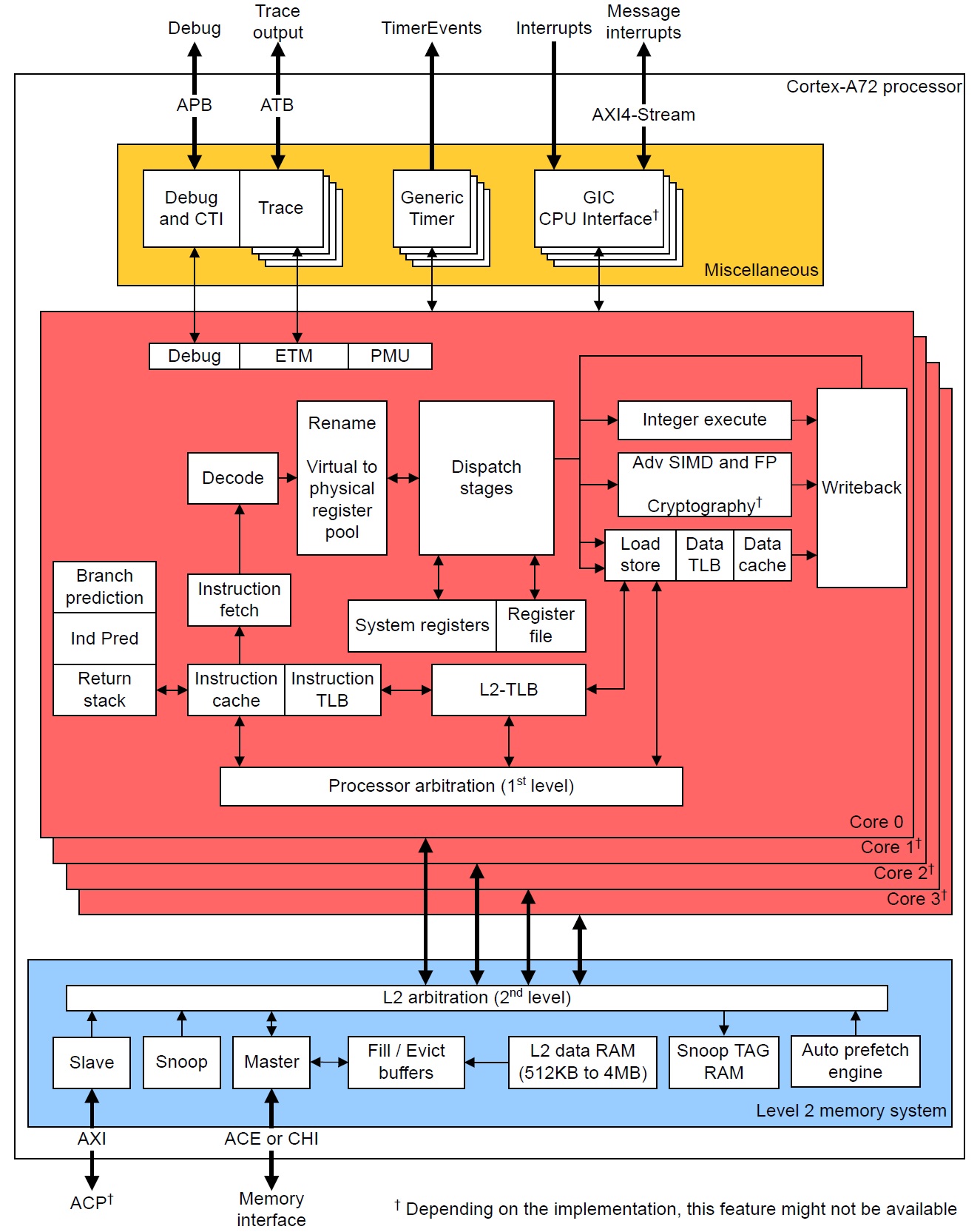
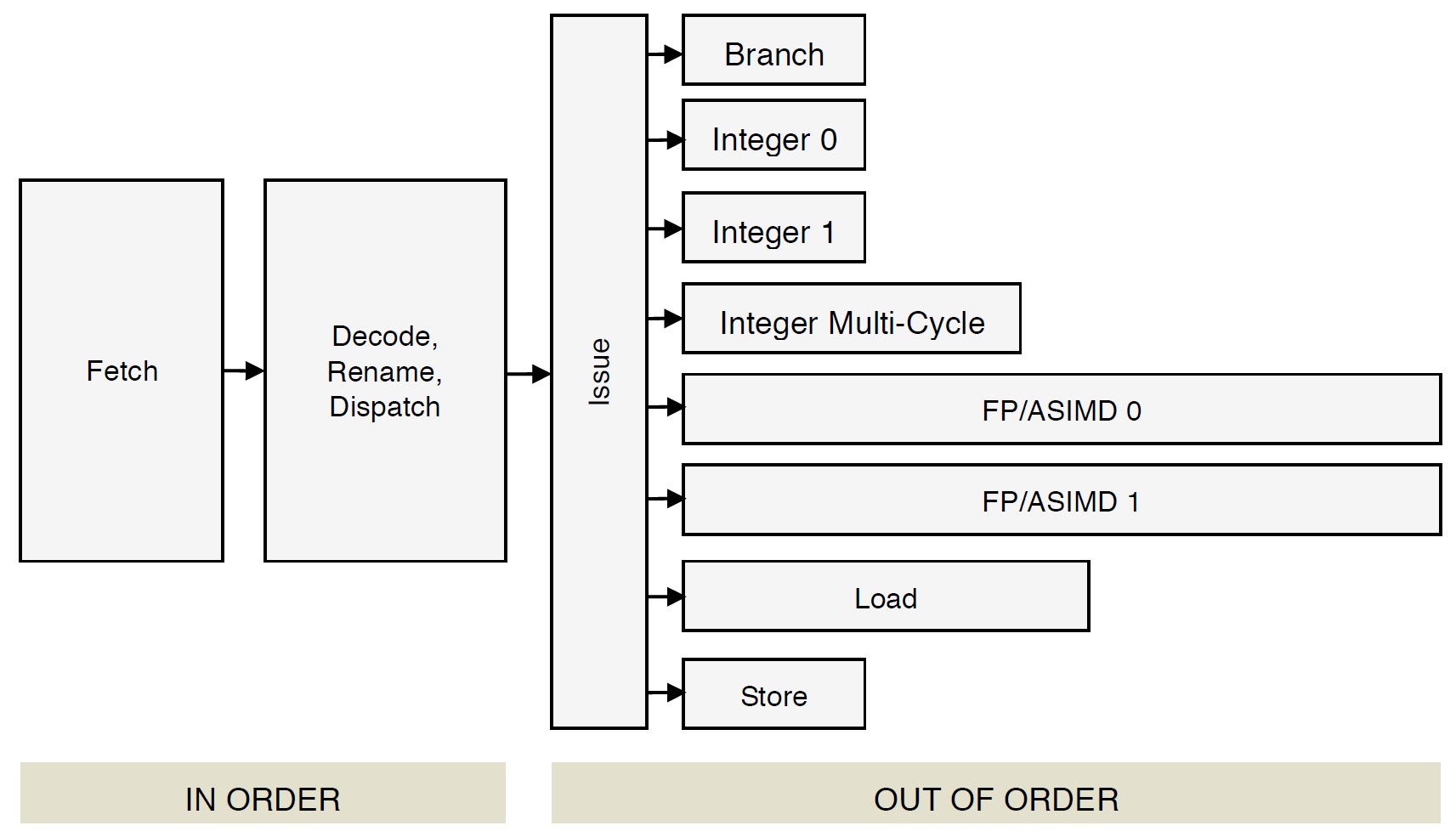
Let’s take a closer look at instruction fetch, decode and dispatch in the Cortex-A72 micro-architecture. These are the “front-end” stages of the core pipeline. The “back-end” of the pipeline consists of the register file(s), execution units and retirement (reorder) buffer. Branch prediction is frequently associated with the front-end since it directly affects instruction fetch.
[Update: This post is part 1 of a two part series. Part 2 discusses ARM Cortex-A72 execution and load/store operations.]
The front-end has one major job: Fetch ARMv8 instructions and keep the back-end execution units as busy as possible.
This page is required reading for Raspberry Pi 4 (BCM2711, ARM Cortex-A72) programmers who want to tune their programs for the ARM Cortex-A72. It is also necessary background information for programmers doing performance measurement with PERF (Performance Events for Linux) on Raspberry Pi 4.
Fetch, decode and dispatch
The Cortex-A72 pipeline has 15 stages. [On-line sources disagree on the length; some sources claim 14 stages.] The front-end stages are:
- Fetch (5 stages)
- Decode (3 stages)
- Rename (1 stage)
- Dispatch (2 stages)
The back-end pipeline stages are:
- Execute (1 to 6 stages depending upon unit)
- Write-back/retirement (2 stages)
Each execution unit has its own pipe:
- Integer 0 (1 stage/cycle)
- Integer 1 (1 stage/cycle)
- Integer multi-cycle (4 to 12 cycles)
- FP/ASIMD 0 (6 to 18 cycles)
- FP/ASIMD 1 (6 to 32 cycles)
- Load L1D cache hit: 4 cycles)
- Store (1 cycle)
- Branch (1 cycle)
See the ARM Cortex-A72 software optimization guide for exact instruction execution latencies.
70 plus years after von Neumann, we still adhere to a linear, sequential program model. In the programmer’s view, there is a program counter (PC) which steps through instructions sequentially, even if some of the intended high-level computations could be performed in parallel by the execution units. Further, we force compilers to lay down instructions in the same linear, sequential fashion.
The front-end’s job is to find instruction-level parallelism (ILP) within the incoming instruction stream. The Cortex-A72 front-end translates ARMv8 instructions into micro-ops. It sends the micro-ops to the back-end functional units for execution and architecture-level retirement.
This all may seem inefficient and crazy and it is. Program representation and execution need a major re-think along the lines of the once-investigated dataflow architecture. Why do and then un-do?
Front-end translation is really two steps: translating ARMv8 instruction into macro-ops and then translating macro-ops into micro-ops. Let’s examine the details.
First, fetch acquires a 16-byte (128 bit quadword) fetch window and it recognizes ARMv8 instructions within the window (and across windows). Then, the decode stages turn the ARMv8 instructions into one or more macro-ops. The decoder will fuse multiple ARMv8 instructions into a single macro-op if such an optimization is possible. Architectural registers are renamed to an internal register file which temporarily holds intermediate results. Next, the macro-ops are translated into micro-ops and the micro-ops are dispatched to the issue queue belonging to the appropriate functional unit. Micro-ops are dispatched into 8 independent issue queues (one queue per execution pipeline). When an instruction successfully completes, it is retired and its result is committed to the architectural machine state. [I will discuss the meaning of “successfully completes” in a minute.]
There are limits on the number of ARMv8 instructions, macro-ops and micro-ops which are processed during a machine cycle:
3 ARMv8 instructions --> 3 macro-ops --> 5 micro-ops
Decode Rename Dispatch
During each cycle, the Cortex-A72 can decode 3 ARMv8 instructions, produce up to 3 macro-ops and dispatch up to 5 micro-ops. There are additional limitations on the number of micro-ops of each type that can be simultaneously dispatched (quoting the Cortex-A72 software optimization guide):
- One micro-op using the Branch pipeline
- Up to two micro-ops using the Integer pipelines
- Up to two micro-ops using the Multi-cycle pipeline
- One micro-op using the F0 pipeline
- One micro-op using the F1 pipeline
- Up to two micro-ops using the Load or Store pipeline
If there are more micro-ops to be dispatched above these limitations, they are dispatched in oldest-to-youngest age order.
According to ARM, most ARMv8 instructions are converted to a single micro-op (average: 1.08 micro-ops per instruction).
Register renaming allows micro-ops to execute out-of-order. Remember, we forced the compiler to lay down ARMv8 instructions in-order. Register renaming allows the micro-ops to execute out-of-order without violating data dependencies between architectural registers. There are 128 physical rename registers.
Speculative execution
Now the really tricky stuff — speculative execution. A basic block is a sequence of “straight-line” code with a single branch instruction at the end of the block. Program control flows into a basic block and is redirected at the end to either the same basic block or perhaps a different basic block.
Generally, basic blocks are about 9 instructions long. The branch at the end may be a conditional branch. The combination of short block length and conditional branching limits the number of ARMv8 instructions which can be aggressively fetched, decoded and dispatched within a single basic block. Without speculative execution, the processor must wait every time a conditional branch needs to be decided.
Enter branch prediction. When Cortex-A72 hits a conditional branch, it predicts the direction: taken or not taken. [More about branch prediction in a minute.] The front-end continues to fetch, decode and dispatch along the predicted control flow path. If the prediction is correct, hurray! The predictor has guessed correctly and the execution units have already been computing useful results. As each ARMv8 instruction completes along a known-to-be correct path, the instructions along the path retire in architectural order. This is the meaning of “successfully completes” above.
If a conditional branch is not predicted correctly (a “mispredict”), the intermediate results along the wrong path are discarded and the fetch stage is told to start fetching from the correct target address. This is called a “re-steer” as in the phrase “re-steering the front-end.” Recovery from a branch mispredict requires a pipeline flush and, yes, it’s expensive — at least 15 cycles.
The Write-back/retirement stage keeps track of the “retire pointer,” that is, the architectural program counter. The retirement stage is some of the most difficult hardware logic to design and it must be correct. The retirement stage maintains a reorder buffer which keeps the books on instruction and micro-op status. The reorder buffer has 128 entries, allowing up to 128 ARMv8 instructions to be simultaneously in flight.
Branch prediction
High performance rides on branch prediction accuracy. If the predictor guesses correctly most of the time, then speculative execution is a win. If the predictor guesses incorrectly, the core must throw away useless results and the execution pipeline stalls.
A deep dive into branch prediction is beyond the scope of this note. So, here’s a sketch. The predictor maintains a Pattern History Table (PHT) which retains the taken or not-taken status of (recent) branches encountered by the core. The predictor also maintains a Branch Target Buffer (BTB) containing the target addresses of these branches. The predictor uses the pattern history to predict the direction of a branch when it encounters the branch again. The BTB supplies the associated target address.
Cortex-A72 allows split BTB entries, accomodating both near branches (small target address) and far branches (large target addresses). That’s why you will see the BTB capacity quoted as 2K to 4K entries. The A72 BTB can hold as a many as 2K large target address (far) and 4K small target addresses (near). The A72 also has a micro-BTB which acts as a cache memory for the main BTB. The micro-BTB has 64 entries.
The branch prediction window is 16 bytes, which has implications for basic block layout. According to the Cortex-A72 software optimization guide, branch targets should be quadword aligned (i.e., 16 byte boundaries) and not more than two taken branches should be included with the same quadword-aligned quadword of instruction memory.
The compiler should really take care of quadword alignment and packing for you. As a higher-level language programmer, you can improve branch prediction by biasing flow conditions toward a true program path or the respective false program path. If a given path (true if-clause or false if-clause) is more frequently executed, the branch predictor should do a better job predicting the underlying conditional branch generated by the compiler.
Cortex-A72 has predictors for subroutine return and indirect branch. The predictor maintains an 8 [?] entry Call/Return Stack which remembers the most recent return addresses. Measurement shows that 8 entries (or so) are enough for most high-level language workloads, covering the most recently called functions.
Bi-mode prediction
There are three sources of interference in a Pattern History Table (PHT):
* Cold miss (compulsory alias)
* PHT capacity miss (capacity alias)
* Conflict miss (conflict alias)
Conflict misses can be reduced by partitioning the PHT or using a different
indexing scheme.
The ARM Cortex-A15 Bi-Mode predictor uses two pattern history tables and a choice predictor to reduce negative interference of branches in different
program modes. Instead of one big PHT, the pattern history is partitioned
into two halves, i.e., two smaller PHTs. A choice predictor table selects
one of the two PHTs. The chosen side delivers the final prediction.
Cortex-A72 does not employ a bi-mode predictor. In case you’re wondering, Cortex-A72 does not have a micro-op loop buffer either.
Want to learn more about Raspberry Pi 4 (Cortex-A72 / Broadcom BCM2711) performance tuning? Please read:
If you have an early model Raspberry Pi, read about the ARM11 micro-architecture here. Please don’t forget my PERF (Performance Events for Linux) tutorial.
Copyright © 2020 Paul J. Drongowski