A few new Casio CT-1000V tips and observations. Hope they’re helpful.
Portamento
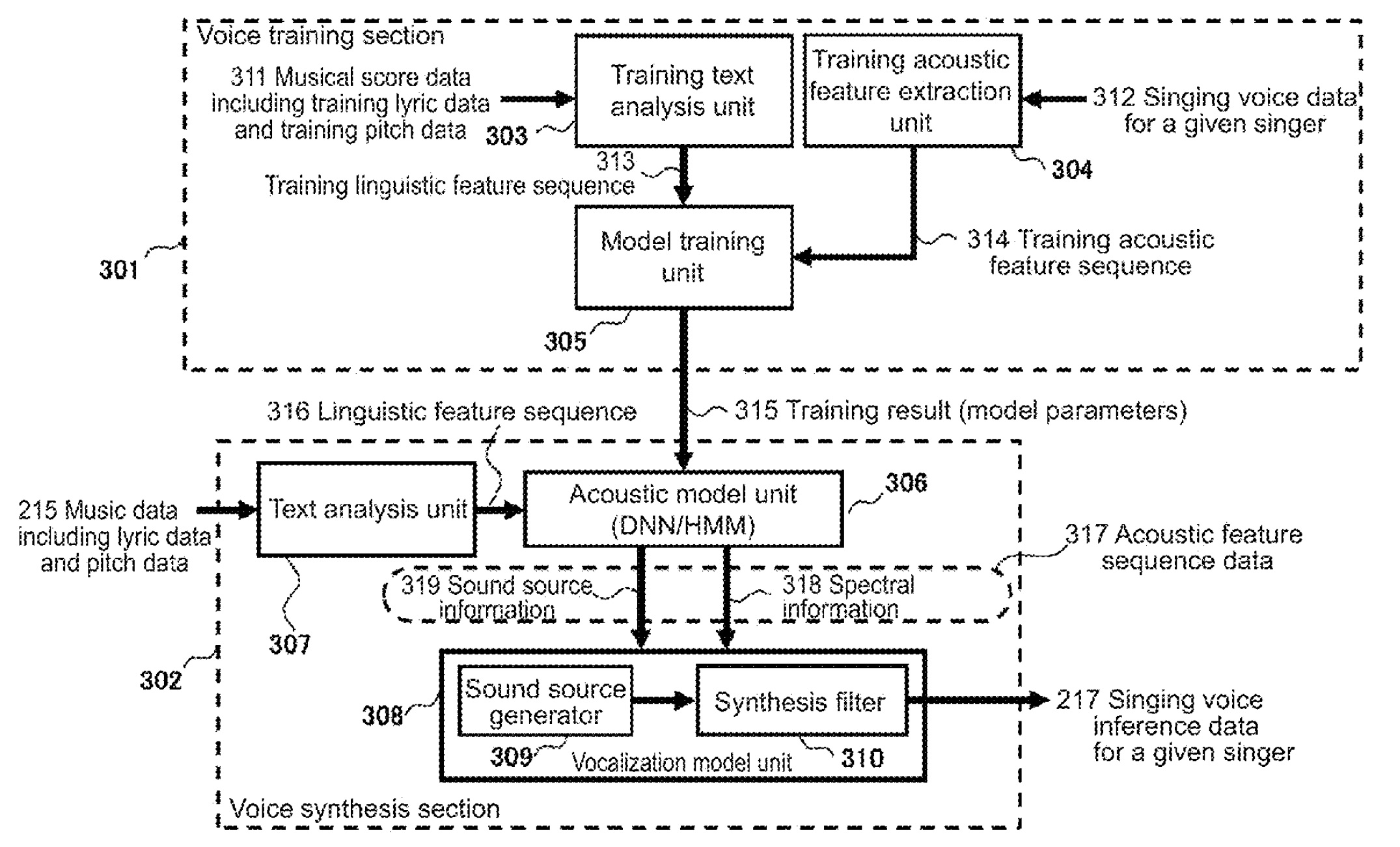
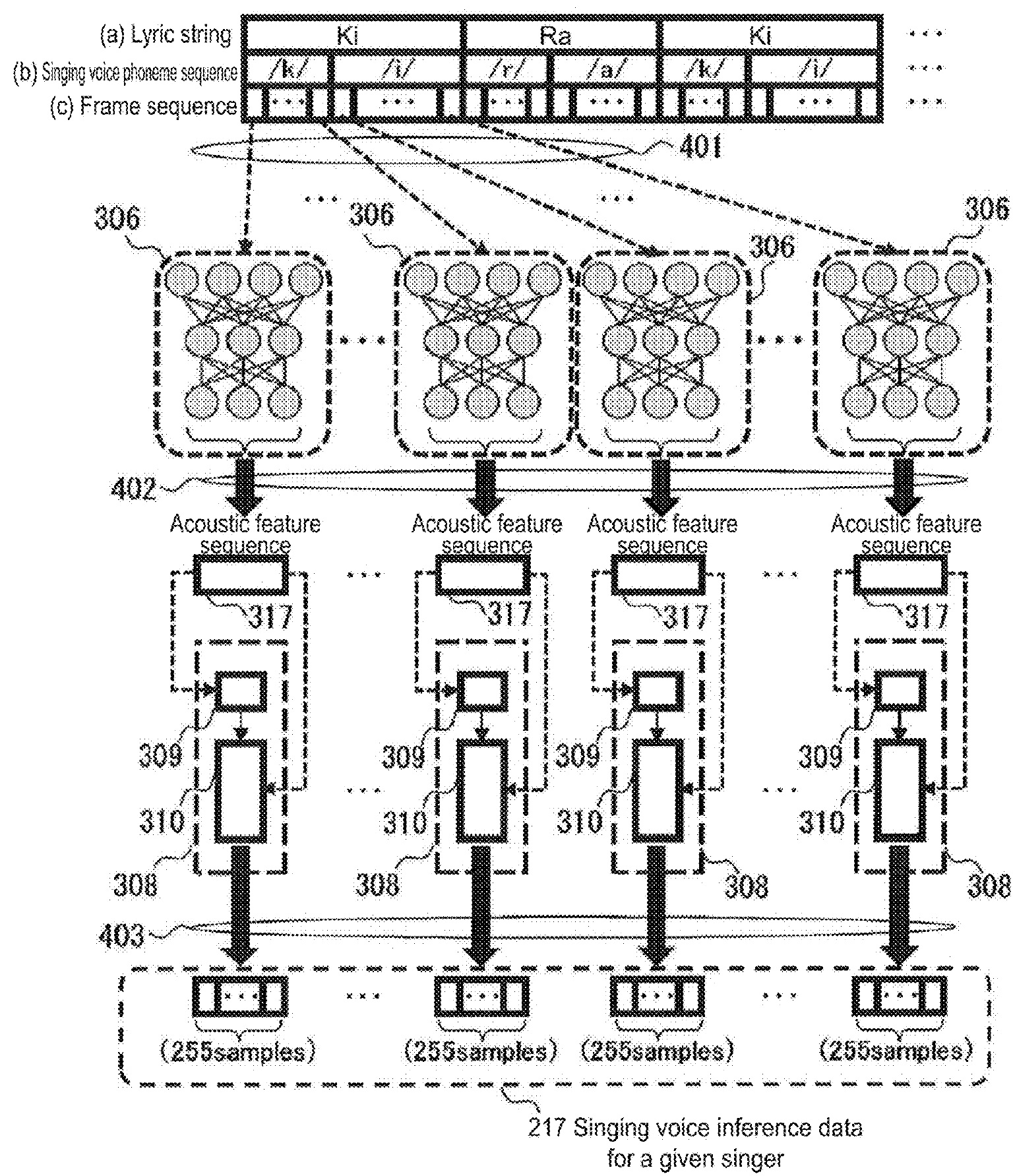
The CT-S1000V (CT-S500) has portamento. Control over portamento is quite flexible. Be prepared to experiment, however, as the interaction between portamento settings is not immediately obvious. Unfortunately, the User Guide is not super helpful as it refers to several terms with “portamento” in the name, e.g., “Upper Portamento,” “Part Portamento”, etc.
All of these tips apply to the CT-S500, too.
There are two different ways to access portameto-related settings: through the MENU button and through the Settings sub-menu.
The MENU parameters allow the following adjustments:
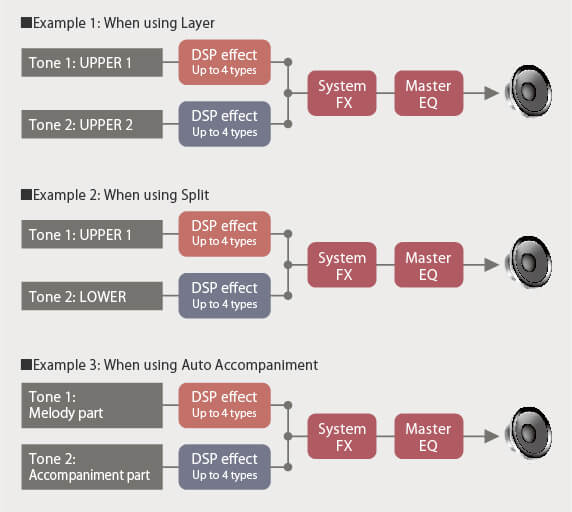
- UPPER PORT: Turn on Upper Portamento.
- PART PORT: Turn on Part Portmento for each part (Upper1, Upper2, Lower).
- TIME: Change portamento time for Upper1, Upper2 and Lower, individually. Each part has its own time.
When Upper Portamento is enabled, you can enable/disable portamento on the Upper part using a front panel button.
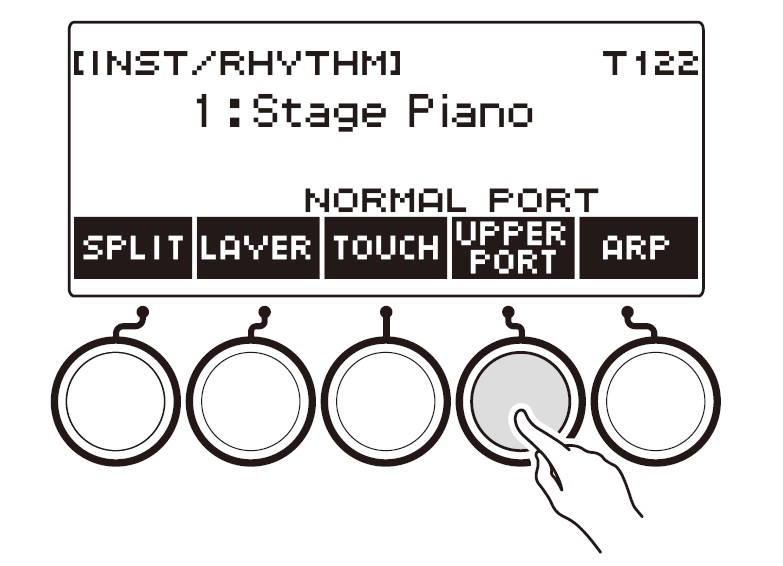
Ah, so which panel button is that? If you press the INSTRUMENT button, the CT-S1000V displays five soft buttons: SPLIT, LAYER, TOUCH, SUS and ARP. The SUS button controls sustain. If you want to control Upper Portamento instead, dive into the Settings sub-menu and scross to “SUS/UPPER PORT button”. Change the value from “SUS” to “UPPER PORT”. Now the INSTRUMENT button shows “UPPER PORT” instead of “SUS”. Pressing the “UPPER PORT” soft button applies portamento to the Upper part. This feature allows you to apply portamento selectively during a solo line.
I hope this brief overview helps when reading the User Guide. I recommend reading the fine print about Upper Portamento because Upper Portamento can override Part Portamento. (Surprise!)
Expression pedal
For some crazy reason, I didn’t hook up and configure an expression pedal on Day 1. In retrospect, one should probably tangle with pedal set-up early just in case pedal settings are saved in user memory locations like CT-S1000V registrations.
The User Guide gives good step-by-step directions concerning pedal set-up. The CT-S1000V is vendor agnostic, thankfully. I have three (!) Yamaha FC-7 pedals and didn’t want to buy another pedal. The CT-S1000V supports two TRS wiring schemes as shown in the diagrams below:
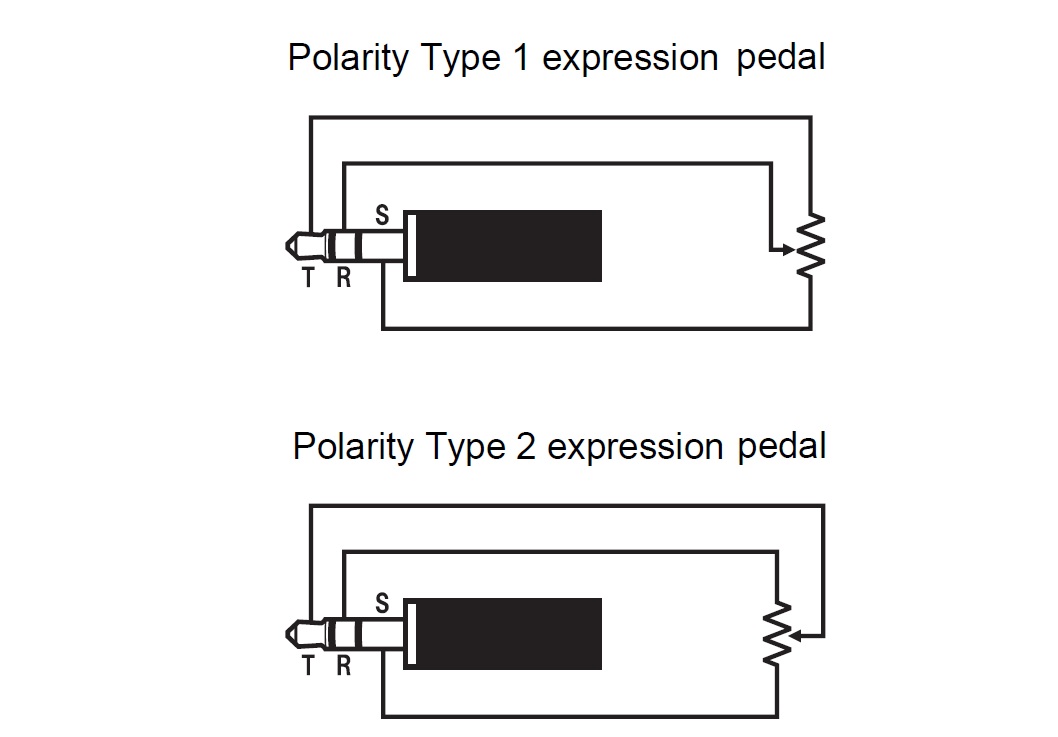
To make a long story short, the Yamaha FC-7 is polarity type 1. The FC-7 resistance is 50K ohms and be sure to go through the simple calibration steps in the User Guide. For reference, the FC-7 TRS signals are:
- Tip: Reference voltage
- Ring: Wiper
- Sleeve: Ground
You wouldn’t believe how many forum posts get this wrong!
Roland, Kurzweil and Fata are polarity type 2. The User Guide confirms operation for the Roland EV-5, Kurzweill CC-1, Fatar VP-25 and Fatar VP-26. Type 2 TRS signals are:
- Tip: Wiper
- Ring: Reference voltage
- Sleeve: Ground
The Roland FV-500L should work, too. Be aware that the EV-5 and FV-500L have a “minimum volume” potentiometer (variable resistor) in series with the main control potentiometer. Turn the minimum volume control to 0 before calibrating. The main control potentiometer resistance is 10K ohms; the minimum volume potentiometer resistance is 50K ohms.
Rant of the day: I have a nice, light-weight Boss EV-1-WL expression pedal. Wish I could use it with the CT-S1000V (and others). No device to device BLE, no 5-pin MIDI, no host compatibility. Arg.
Are pedal settings really stored?
I posted this question on the Casio Music Forums site. Even though the User Guide claims the pedal settings are stored in MY SETUP and registrations, I haven’t seen evidence. If you change the pedal settings and load a registration (or MY SETUP), the changed settings remain.
I hope that Casio will clarify.
Drawbar organ tones
As mentioned earlier, I pulled together a bank of drawbar organ registrations. I settled on the following tones:
Gospel Organ 2 Mellow
Rock Organ 2 Mellow
Elec.Organ 1 Bright church-y for hymns
Elec.Organ 6 Simmerin' for grease
In all four cases, I split the keyboard putting the “Organ Bass” tone in the left hand. I like the way Organ Bass holds down the low-end and doesn’t sound swirly. Split point is E4.
Movin’ on to pipe organs…
Copyright © 2022 Paul J. Drongowski