Maybe it’s the first day of the regular NFL season or the phase of the moon. Here’s a recap of a few questions that came into the forums.
How are arranger/synth preset voices stored? First, one may ask, “How is a preset represented?” Typically, a preset voice consists of waveforms (AKA “samples”) and voice (meta-)data. The voice data control how the sample-playback engine applies filtering, amplitude envelope, modulation and so forth. The waveforms, of course, provide the basic digital audio data.
There is such a broad range of arranger/synth products at different price points, that the amount of storage and the kind of storage varies quite a lot.
The lowest of the low in the Yamaha range: PSS-A50, -E30, -F30, PSR-F51. Presets are stored on a 2MByte serial flash ROM and are loaded into the processor (SWLL) at start-up. The 2MBytes include code, too! Tone generation is integrated into the SWLL. Insanely small, and very low cost.
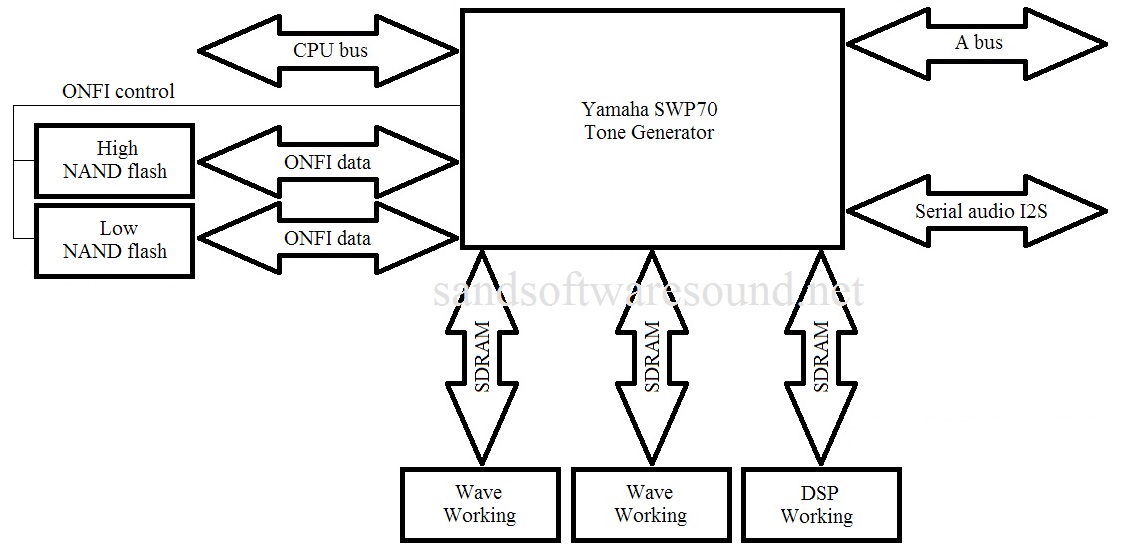
The highest of the high in the Yamaha range: Genos. Factory presets are stored in four 1GByte ONFI NAND flash devices. Expansion memory consists of two 1GByte ONFI NAND flash devices. Wave memory connects directly to external tone generators (SWP70).
I’ve looked at the diagrams for Genos and I’m not sure about the size and function of those memory units, especially Genos USER memory and expansion memory.
Yamaha confuses people when they speak of “user memory,” “internal memory,” etc. They are usually referring to logical, user visible storage.
When getting down to the hardware level, there are many different physical memory units. since we’re not discussing fairy dust or magic, the logical storage must be assigned to one or more physical memory units. And, of course, the physical memory units themselves may be composed of multiple integrated circuits. The other dimension is “what communicates to what.” Memory is passive and needs a processor to initiate reads and writes and to do something with all that data. At the physical level, a memory unit essentially belongs to a single processing unit (host computer, tone generator) and directly communicate with it.
Sometimes I think of the SWP70 as a parallel processor just like a GPU. The CPU/SWP70 is not exactly analogous to host CPU plus GPU, however. Graphics memory is shared between CPU and GPU. The SWP70 does not share its waveform memory with anybody — it’s dedicated to the tone generator. That’s why installing an expansion pack (voice library) is kind of slow and technically complicated, and why a Genos reboot is required.
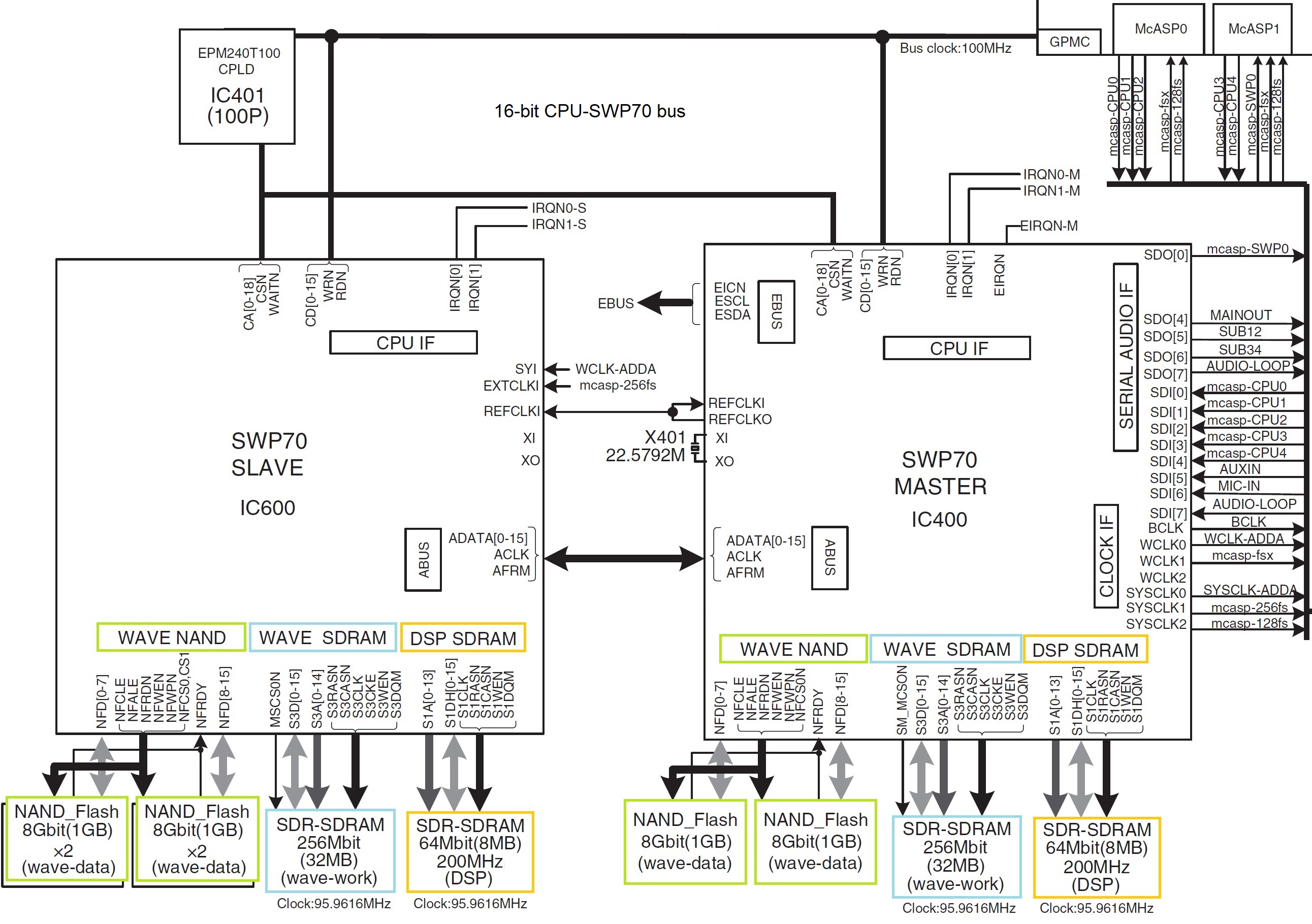
Staying with Genos, Genos has two SWP70 tone generators: one handles factory presets and the other handles user expansion voices. The factory SWP70 has 4GBytes of flash memory while the expansion flash memory has 1GB of flash memory. That’s physical memory. Yamaha boosted the effective capacity to 3GB expansion through compression.
The SWP70s also have DSP RAM. As a user, you never know about this memory. It’s scratchpad memory for DSP effects. Physically, the DSP RAM is completely separate and independent from the waveform memory, and communicates with only its parent SWP70.
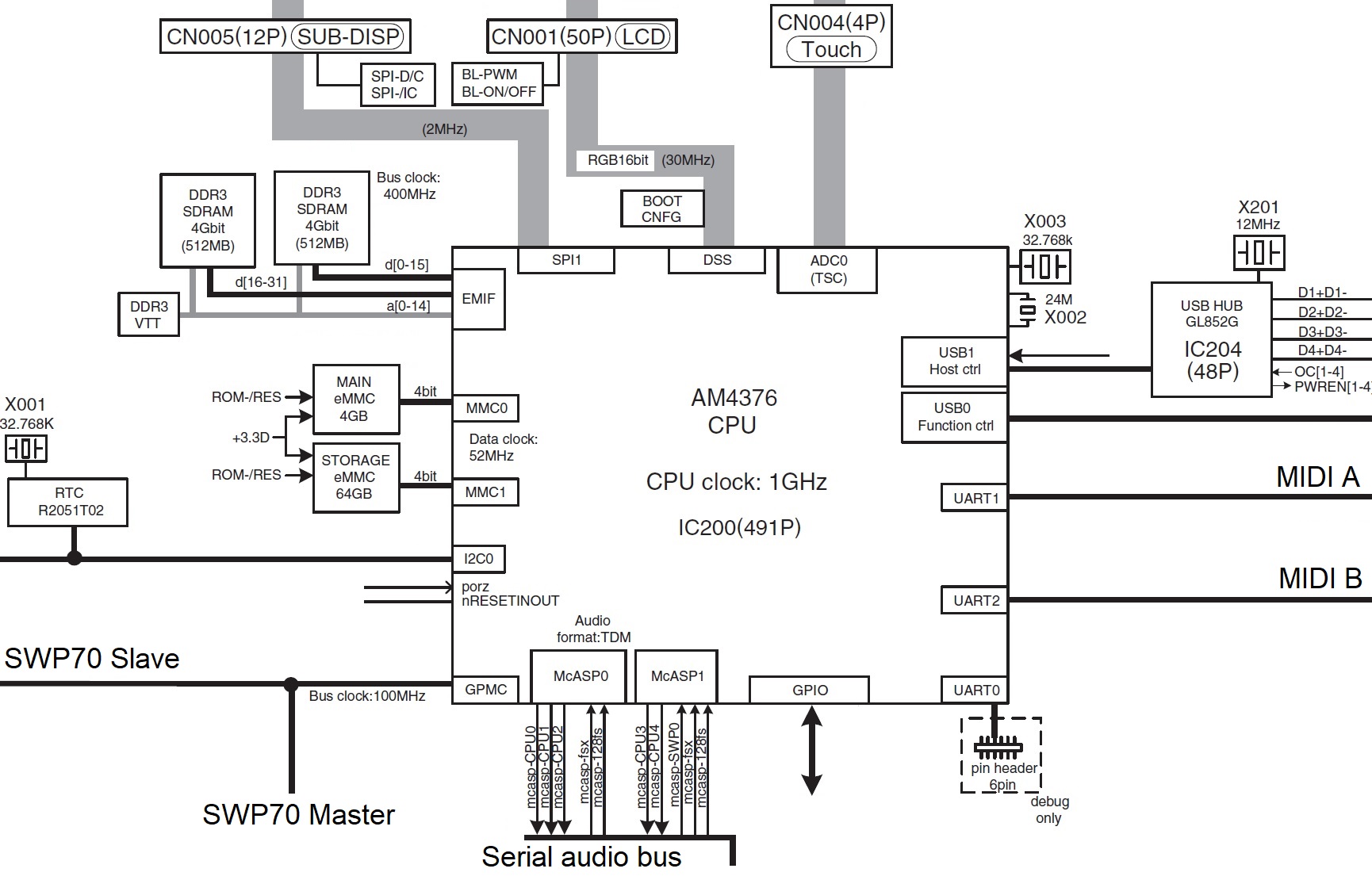
The host CPU has two kinds of memory (as determined by its bus interfaces): 1GB of working RAM on the CPU memory bus (EMIF) and two embedded eMMC memory devices that act like solid state storage drives (MMC0 and MMC1). As far as a user is concerned, the user never sees the 4GB eMMC drive (MMC0) just like you don’t see the DSP RAM; it’s hidden. The MMC0 drive contains the Linux operating system kernel and the root file system.
The user sees only part of the second 64GB eMMC drive (MMC1). The user sees the logical storage which Yamaha calls “Internal memory” or “USER drive.” What’s in the remaining 6GB? I don’t know — Yamaha haven’t left any clues.
What about Montage and its 5.67GByte waveform memory? 5.67GB is the capacity when the waveforms (samples) are compressed. Again, this is logical storage capacity.
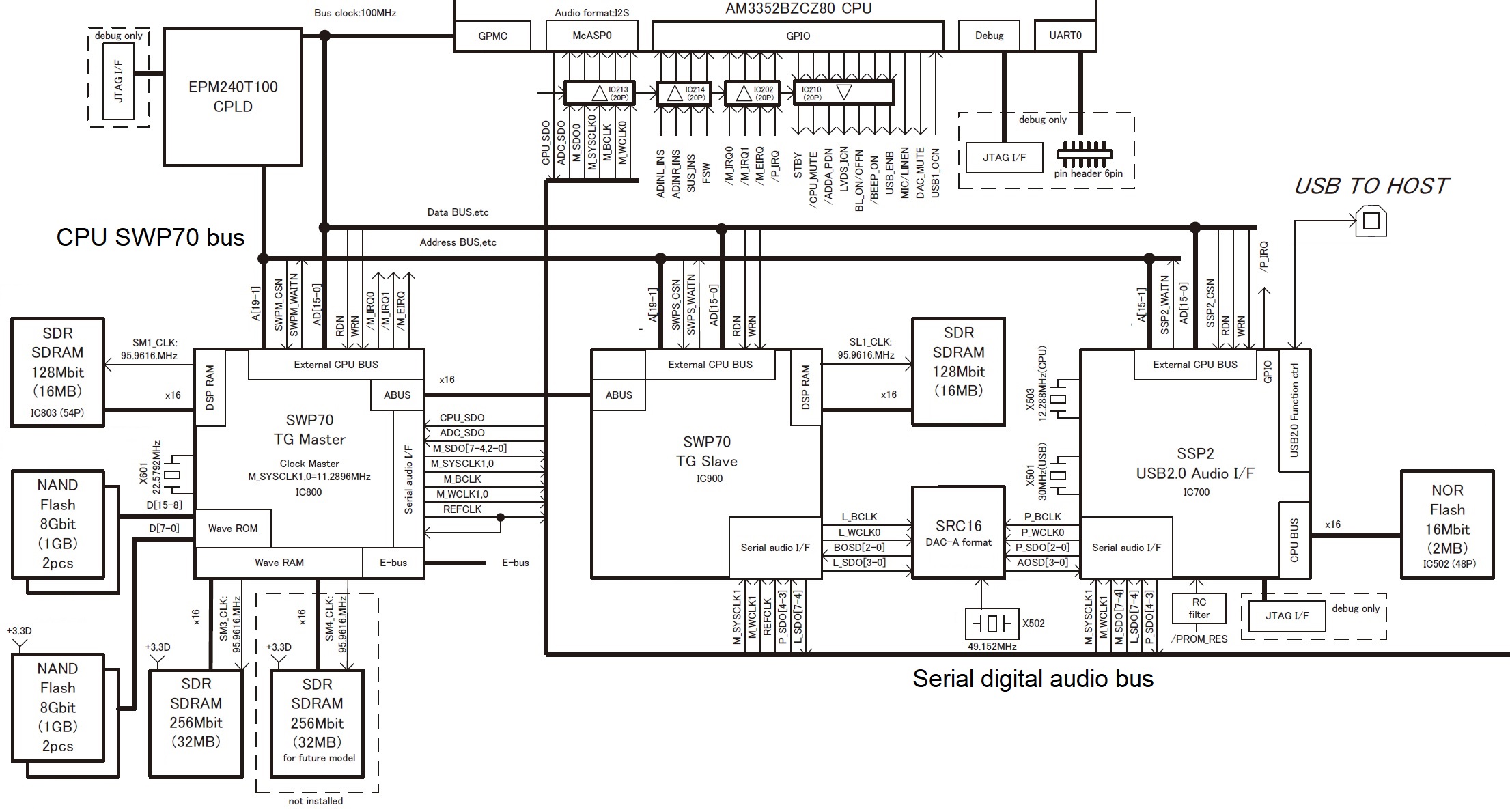
Montage has two SWP70s. One SWP70 is dedicated to FM-X and it does not have waveform memory. The second SWP70 handles AWM2 synthesis (sample playback) and has waveform memory connected to it. The waveform memory consists of four 1GByte devices totaling 4GBytes. Thanks to Yamaha’s proprietary compression, Montage stores 5.67GBytes-worth of data in the physical waveform memory. The remaining space, 1.75GB physical, is available for user samples.
How does sample capacity relate to price? It doesn’t. Component cost is outweighed by manufacturing costs, software development cost and sound design cost.
If the memory components are so cheap, why isn’t there more waveform memory? If there was more, then you wouldn’t buy the Mark II model, would you? 🙂
I understand that E30/F30 do NOT offer velocity sensitivity. My question is about the internals. Is it confirmed that it’s a keybed with two switches per key, that just aren’t supported in software?
Yes, you need to be careful here. There are hardware model differences: E30 and F30 are not velocity sensitive. A50 is velocity sensitive.
There are two different keybed printed circuit boards (PCB). Yamaha part number VAY27800 for F30/E30 and VAY28500 for A50. The A50 PCB has the necessary diodes installed for velocity sense. The F30/E30 PCB does not have the diodes. Further, the A50 board has a 12-pin connector while the F30/E30 board has an 11-pin connector — perhaps to avoid assembly mistakes.
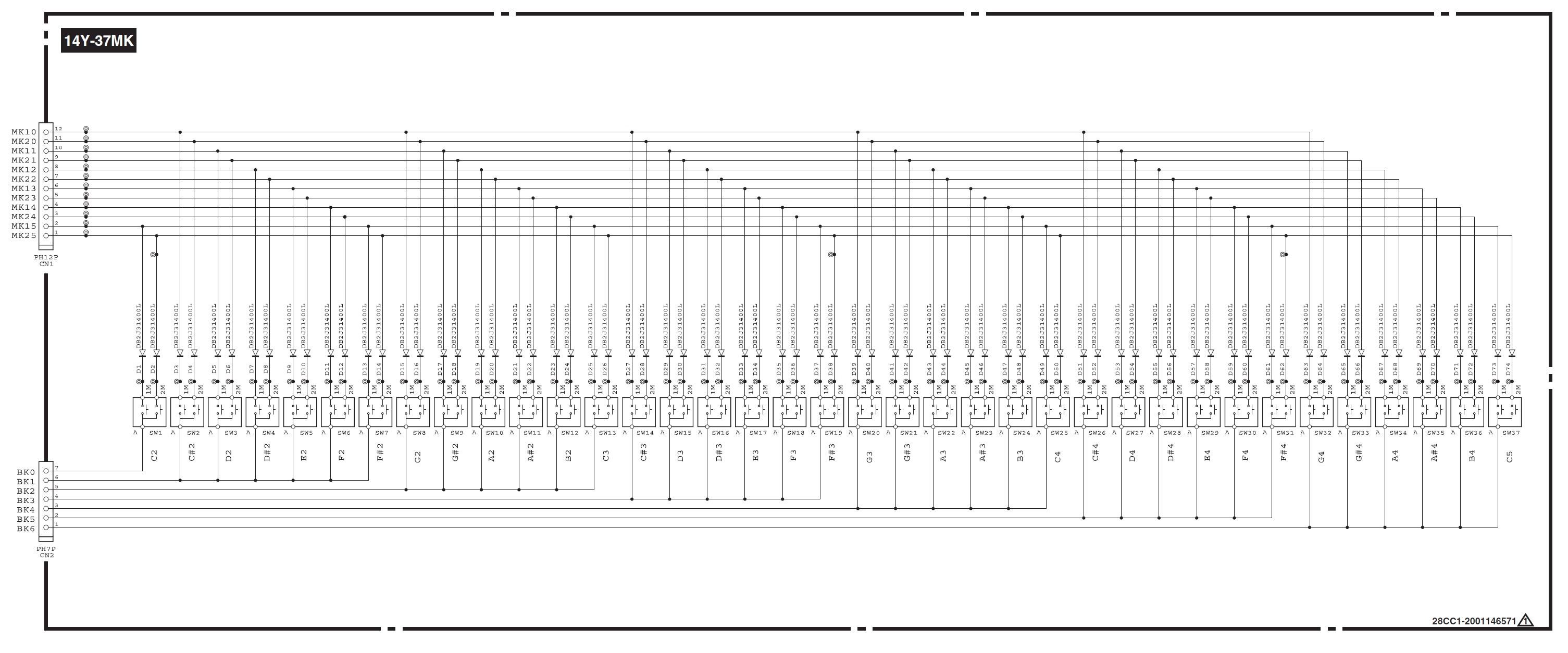
Is velocity sense worth the extra bucks? There may be other differences, too, but these differences are plainly visible.
And the usual caution/disclaimer — kiss the warranty good-bye! For the money, the PSS should be good mod-fodder. Korg probably sold a mess o’monotron that way.
Copyright © 2021 Paul J. Drongowski